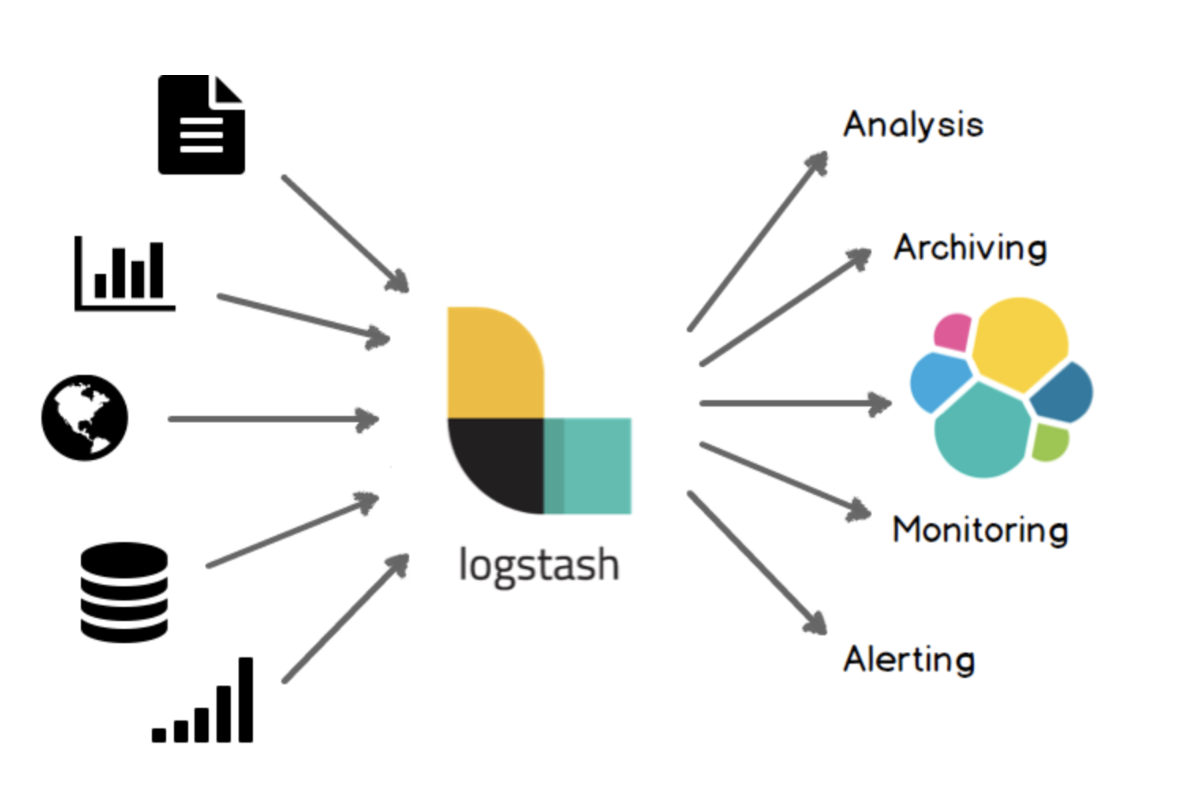
MySQL에 적재되는 데이터를 Elasticsearch에 복제하여 사용하려는 요구가 있다. 다양한 방법이 있는 듯하다. logstash input - jdbc plugin output - elasticsearch plugin fluentd input - mysql-query, mysql-prepared-statement etc.. output - elasticsearch 이 중 fluentd에 mysql-replicator가 있어서 이 부분에 대해서 구동해본 내용 정리. [mysql-replicator?] github: https://github.com/y-ken/fluent-plugin-mysql-replicator GitHub - y-ken/fluent-plugin-mysql-replicator: F..