목차
데이터를 다룰 때 타입에 따라 2가지 특징이 있었다
- 원시형: 빠른 속도. 편리한 기능 부족
- 참조형: 느린 속도. 편리한 기능
그렇다면 복수 개의 값을 처리하려면 배열을 사용하는 것을 고려해볼 수 있을 것이다. 하지만 배열의 경우 크기를 마음대로 조절할 수 없는 등 불편한 점이 있다.
이런 부분에 신경쓰지 않으며 편리한 기능들을 부가적으로 제공하는 자료형에 대한 요구가 계속 있었는데, 자바 1.2 버전에서 컬렉션 프레임워크를 통해 언어 차원에서 공식적으로 이를 제공하기 시작하였다.
[컬렉션 프레임워크 특징]
- 일관성 있는 API: 동일한 기능은 동일한 API를 갖는다. (List, Set 모두 데이터를 삽입할 때 add()를 사용한다)
- 개발 비용 절약: 필수 데이터 구조와 알고리즘을 제공하여 개발자가 일일이 알고리즘을 구현할 필요가 없다.
- 고성능: 최적화를 모두 해놓았다.
- 재사용 가능: 공통 표준을 제공하므로 과거에 작성한 코드도 현재 버전에 호환된다.
[컬렉션 프레임워크의 종류]

** Map은 별도 정의되어 있다.
- List: 순서대로 element를 모아놓는 배열과 유사한 구조.
- Set: List와 유사하지만 중복을 허용하지 않는다.
- Queue: 큐 자료구조. Deque는 양쪽에서 삽입과 삭제를 할 수 있는 스택+큐의 구조를 갖는 자료 구조이다.
- Map: Collection 인터페이스를 확장하지 않고 별도로 구현되어 있다. 별도로 구성된 만큼 List, Set과는 조금 다르게 동작하며 메서드 명칭도 조금 다르다.
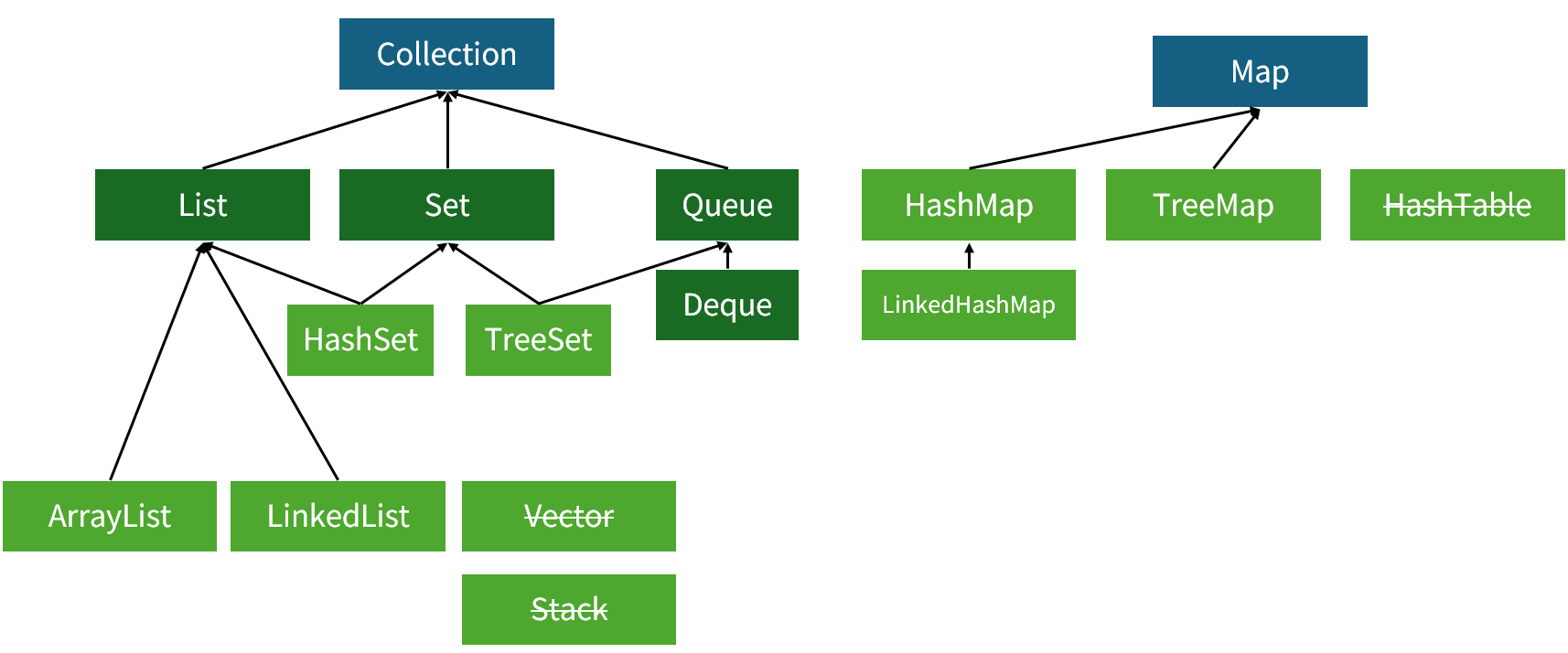
** 사용하지 않으면 취소선으로 표현
List, Set, Map은 모두 인터페이스이다. 그렇기 때문에 실제 구현체들이 필요한데 구현체까지 포함된 다이어그램은 위와 같다.
List
- ArrayList
- 배열 형태의 기본적인 리스트.
- 내부적으로 배열을 사용하기 때문에 크기를 늘리려면 배열 크기를 늘리기위한 복사가 발생할 수 있다.
- 인덱스를 통한 검색이 가능해서 시간복잡도가 O(1)을 가진다.
- 데이터의 크기가 자주 변하지 않고, 읽기(access)가 자주 일어나는 경우에 적합
- LinkedList
- 리스트를 연결 리스트로 구현한 자료형.
- 검색 시 처음부터 찾아야하기 때문에 O(n)의 시간복잡도를 가진다.
- 삽입과 삭제가 자주 일어나는 상황에서 유리하지만, 읽기 속도는 느림
Set
- HashSet
- 순서를 유지하지 않음
- 저장 순서가 중요하지 않고 빠른 삽입/삭제가 필요한 경우 사용
- LinkedHashSet
- 삽입된 순서를 유지함.
- 해시 외에 순서를 유지하기 위해 연결 리스트를 사용하므로 좀 더 많은 리소스가 필요함.
- 삽입 순서를 유지하면서도 hashset을 사용하고 싶은 경우에 사용
- TreeSet
- 내부적으로 이진탐색트리를 사용하기 때문에 검색속도가 빠름 (HashSet에 비해서는 느림)
- 이진탐색트리를 위해 항상 정렬하기 때문에 삽입/삭제가 잦은 경우 성능이 떨어질 수 있음.
- 정렬된 데이터를 원할 경우 사용
Map
- HashMap
- 해시 테이블 구조의 자료형.
- 입력 순서를 보장하지 않는다.
- LinkedHashMap
- 연결리스트를 통해 입력 순서가 유지된다.
- TreeMap
- 값에 따라 순서를 정렬한다.
- 내부적으로 레드-블랙 트리로 구현되어 있다.
- 정렬 순서도 임의로 지정할 수 있어서 특정 조건에 따라 정렬된 상태가 필요하다면 사용한다
[초기 자료형의 성능 문제]
위의 다이어그램에서 Vector, HashTable은 지금은 더 이상 사용하지 않는다.
자바는 1.0 정식 버전을 출시할 때 부터 목록형 자료형에 대한 고민이 많았고 초기에는 C++의 영향을 받아서 Vector와 HashTable을 만들었다고 한다.
당시에는 공통 인터페이스가 없어 각자 구현을 했다고 한다.
그래서 아래처럼 사용했다고 한다.
Vector<Intger> vector = new Vector<>();
vector.addElement(1);
vector.addElement(2);
사실 공통 인터페이스가 없더라도 크게 상관은 없을 수 있다.
하지만 이보다 더 큰 문제인 성능 이슈가 있었다고 한다.
Vector는 기본적으로 모든 메서드가 동기화되어 있어, 멀티스레드 환경에서 안전하게 사용할 수 있으나 그러나 이로 인해 성능 저하가 발생할 수 있고 특히, 동기화가 필요 없는 경우에도 불필요한 오버헤드가 추가되는 것이 문제였다.
이외에도 제네릭 미지원, 배열 크기 부족 시 유연성 부족 등의 이유로 Vector는 더 이상 사용되지 않고 있다.
비슷한 사례로 StringBuffer도 모든 메서드가 동기화로 동작한다. 하지만 하위 호환성을 위해 수정할 수 없었고 현재는 StringBuilder로 대체되었다.
'Java' 카테고리의 다른 글
| 원시 자료형 (Primitive Type) 과 참조 자료형 (Reference Type) (0) | 2024.10.03 |
|---|---|
| Java가 빌드되고 실행되는 과정 (3) | 2024.10.03 |
| 함수형 인터페이스 (Functional Interface) 에 대해 (2) | 2024.10.03 |
| 제네릭 (Generic) 에 대해 (1) | 2024.10.03 |
| Java의 주요 특징 (1) | 2024.10.03 |