우아한 테크 세미나 Virtual Thread 내용 정리
목차
[세미나 링크]
https://www.youtube.com/live/BZMZIM-n4C0?si=-OcKsmlNlpjjhQk1
[내용 정리]
일단 시작하기전에 virtual thread는 무조건 좋은 기술이 아니다. 상황과 필요에 맞게 사용하라고 한다.
목차는 아래와 같다.

먼저 VT를 소개하는 시간이다.

회원 프로덕트 팀은 전사 보급을 위한 게이트웨이 시스템을 개발했다고 한다. 전사 대상이기 때문에 안정성과 처리량에 대한 고민이 많았다고 한다.
그림을 보면 게이트웨이 시스템은 타 시스템의 앞에 위치에서 요청에 대한 사용자 인증같은 전처리를 수행 후 후속 시스템에 연결하는 방식이었다. 그래서 다양한 시스템의 트래픽이 대부분 유입된다.
그래서 선택지가 2개 있었다고 한다. 이 중에 Kotlin Coroutine을 선택했다고 한다. Java Project Loom은 정식 feature도 아니고 reference도 별로 없었다고 한다.
- Kotlin Coroutine
- Java Project Loom

이렇게 Kotlin으로 게이트웨이 시스템을 운영하던 중 JDK21에 virtual thread가 나오면서 deep dive를 시작했다고 한다.
그래서 VT는 자바의 경량 스레들 모델이고 Project Loom으로 시작되었다.
스레드 생성과 스케줄링 비용이 기존 스레드보다 저렴하고, 스레드 스케줄링을 통한 논블로킹 IO를 지원하며 기존 스레드를 상속해서 기존 코드에 완벽히 호환된다고 한다

이걸 하나씩 살펴본다. 우선 스레드 생성 비용이 저렴한 부분이다.

기존의 자바스레드는 생성비용이 커서 스레드풀을 사용하는 이유가 되기도 했다.
그리고 스레드를 생성할 때 마다 메모리의 일정 공간을 잡아먹는다. (최대 2MB)
또한 자바의 스레드는 OS에 의해 스케줄링 되기 때문에 스레드의 생성/관리가 시스템콜에 의해 처리되어야해서 이 오버헤드가 또 추가로 발생했다.

반면 VT의 경우 스레드 생성비용이 작고 스레드풀개념 조차 없다고 한다. 요청이 들어올때마다 항상 새로만들고 파괴한다고 한다. 또한 메모리도 적게 사용한다. (수십 KB정도만 사용)
또한 스케줄링도 OS가 아닌 JVM내에서 이루어진다고 한다. (시스템콜로 인한 오버헤드 없음)

이걸 표로 정리하면 아래와 같다.
일반 스레드보다 공간도 적고, 생성시간도 적고 컨텍스트 스위칭 시간도 적은 것을 볼 수 있다.
여기까지가 VT의 장점이었다.

과연 이걸 믿을 수 있을까? 단순한 실험을 해보았다고 한다.
스레드 생성이 빠르다고 했으니 스레드를 100만개 만들어보는 실험을 했다.

코드를 보면 정수 백만까지 해서 new Thread로 새로운 스레드를 만들었다. 일반 스레드의 경우 31초 걸렸다고 한다.
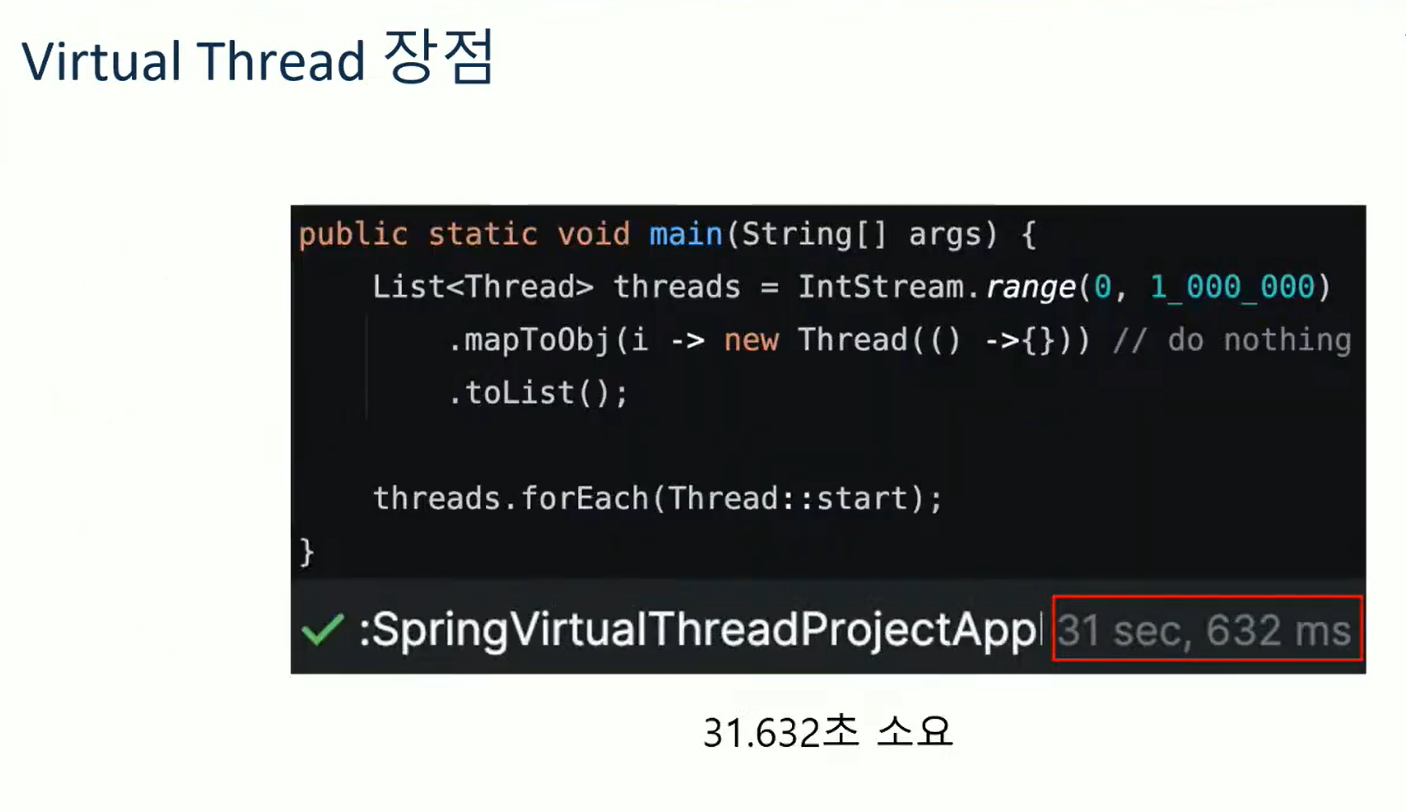
반면 VT의 경우 0.375초가 걸렸다고 한다.

그래서 결론은 기존 스레드 대비 98.8% 스레드 생성속도가 더 빠르다는 것을 알 수 있었다.
이 이유가 메모리/시스템콜때문일까..? (이 부분은 뒤에서 나온다)

다음 장점은 논블로킹 IO를 지원하는지 여부이다.

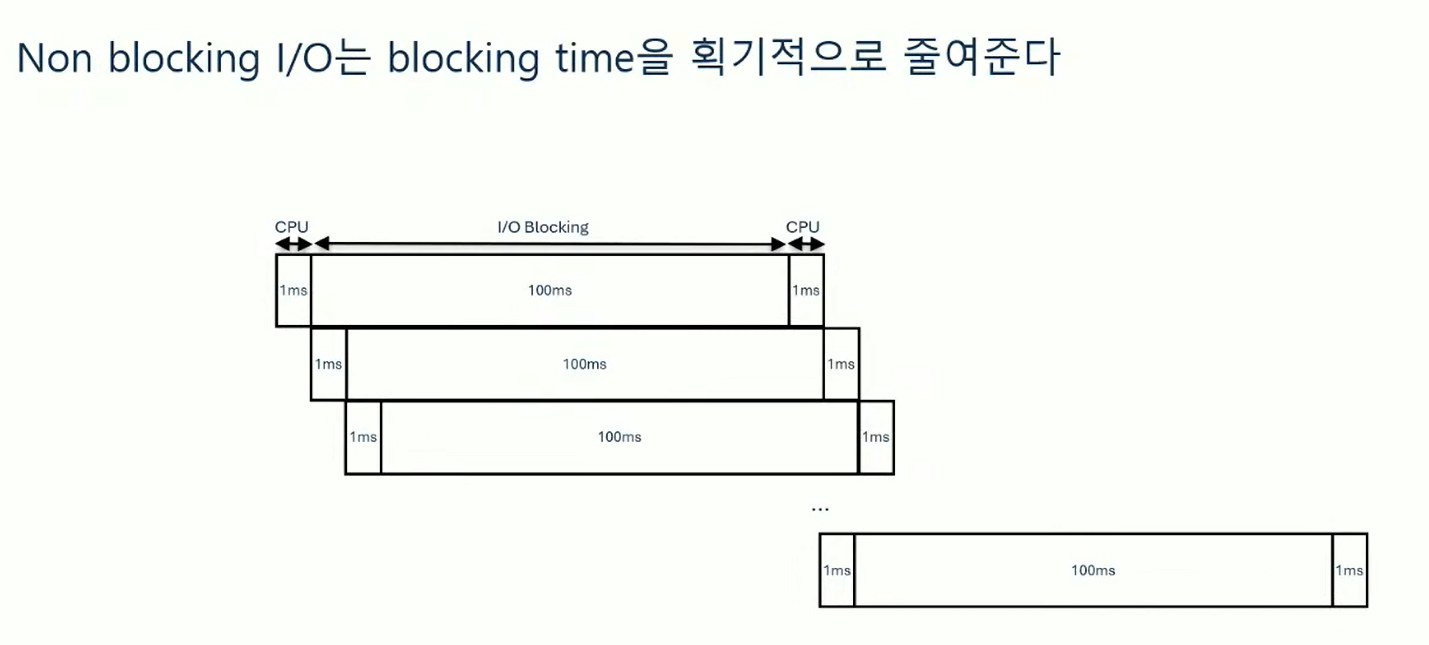
요즘은 복잡한 서버 환경 등으로 인해 점점 더 블로킹 시간이 증가하고 있다.
기존의 thread per request 모델은 이러한 블로킹 시간이 병목이 되는 경우가 많다.

그래서 이를 해결하기 위해 논블로킹 IO 방식이 나오게 되었다. 요즘 서버 환경에서는 매우 중요한 패러다임이다.
대표적인 기술로 spring WebFlux가 있다. Event Loop를 통해 논블로킹IO를 지원했다.

그래서 virtual thread도 동일하게 논블로킹IO를 지원하는데 그 방식이 다르다고 한다.
JVM 스레드 스케줄링 방식과 Continuation을 활용한 방식으로 논블로킹 IO를 구현했다고 한다.
이 두개념이 생소할 수 있지만 뒤에서 살펴본다고 한다.

그럼 두번째 실험도 진행한다. VT로 구성된 서버는 논블로킹 IO로 동작하는지 확인해본다.
실험방법은 톰캣 서버를 10개 띄우고 API는 10초가 소요되는 것을 구현한다.
그리고 클라이언트에서 이를 100회 호출하도록 했다.
이게 블로킹 방식으로 처리하면 100초걸린다.
100개의 호출을 10개 스레드로 호출하니까 한 번에 10개씩 처리하고 각각 10초가 소요되니까 100초가 걸린다.

그래서 일반 스레드로 돌리니 실제로는 130초 걸렸다.

VT로 돌리니 10초걸렸다.

즉 결과적으로 논블로킹IO로 동작하고, 요청을 동시에 처리했다는 것을 볼 수 있다.

다음으로 기존 스레드를 상속받는 부분에 대해 살펴보자.
VT는 기존 스레드를 상속한다.

정의를 보면 BaseVirtualThread를 상속하고 그건 다시 Thread를 상속한다.
즉, 기존 스레드와 호환이 된다는 뜻이다.

ExecutorService도 마찬가지로 virtualThread의 executorService로 대체할 수 있도록 되어있다.
이처럼 VT는 일반 자바와 완벽히 호환되도록 되어있어서 코루틴이나 webflux에 대한 러닝 커브 없이 바로 적용할 수 있다는 장점이 크다.

정리를 해보면 VT의 장점은 3가지이다.

여기까지 장점에 대해 살펴봤고, 그럼 VT가 무엇인지 알아보자.

우선 일반 스레드의 특징을 살펴보자. 자바의 스레드는 플랫폼 스레드라고 부르고, OS에 의해 스케줄링되며 커널 스레드와 1:1맵핑된다. 또한 작업 단위로 Runnable을 사용한다.

그래서 자바 앱은 2가지 영역에서 수행된다.
커널 영역은 OS라고 부르는 영역이고(여기에 커널 스레드가 있다), 유저영역은 우리의 JVM영역이다. (여기에 플랫폼 스레드가 있다)
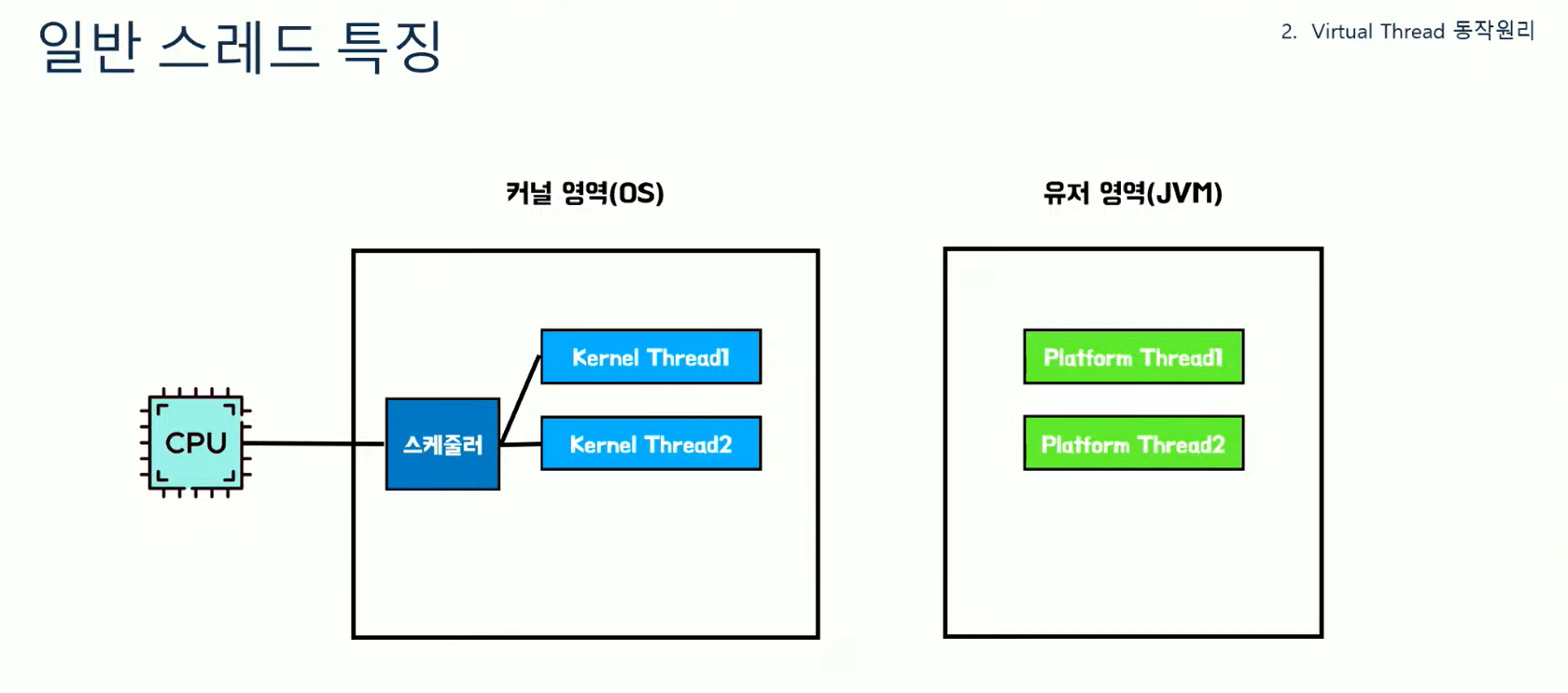
이 둘 사이를 통신하기 위한 도구가 필요한데 그게 JNI라고 한다. 그래서 이를 통해 커널 스레드와 플랫폼 스레드를 1:1로 맵핑하게 된다.

우리가 플랫폼 스레드를 생성하는 과정을 보면 JVM에 플랫폼 스레드에 생성하고 start하면 커널영역에 커널 스레드를 만들어달라고하고, 그 결과로 OS에 커널 스레드가 생성되게 된다.

이걸 코드로 보면 Thread::start할 때 start0를 호출하고 이게 native 메서드이다. 즉, 시스템콜을 한다.

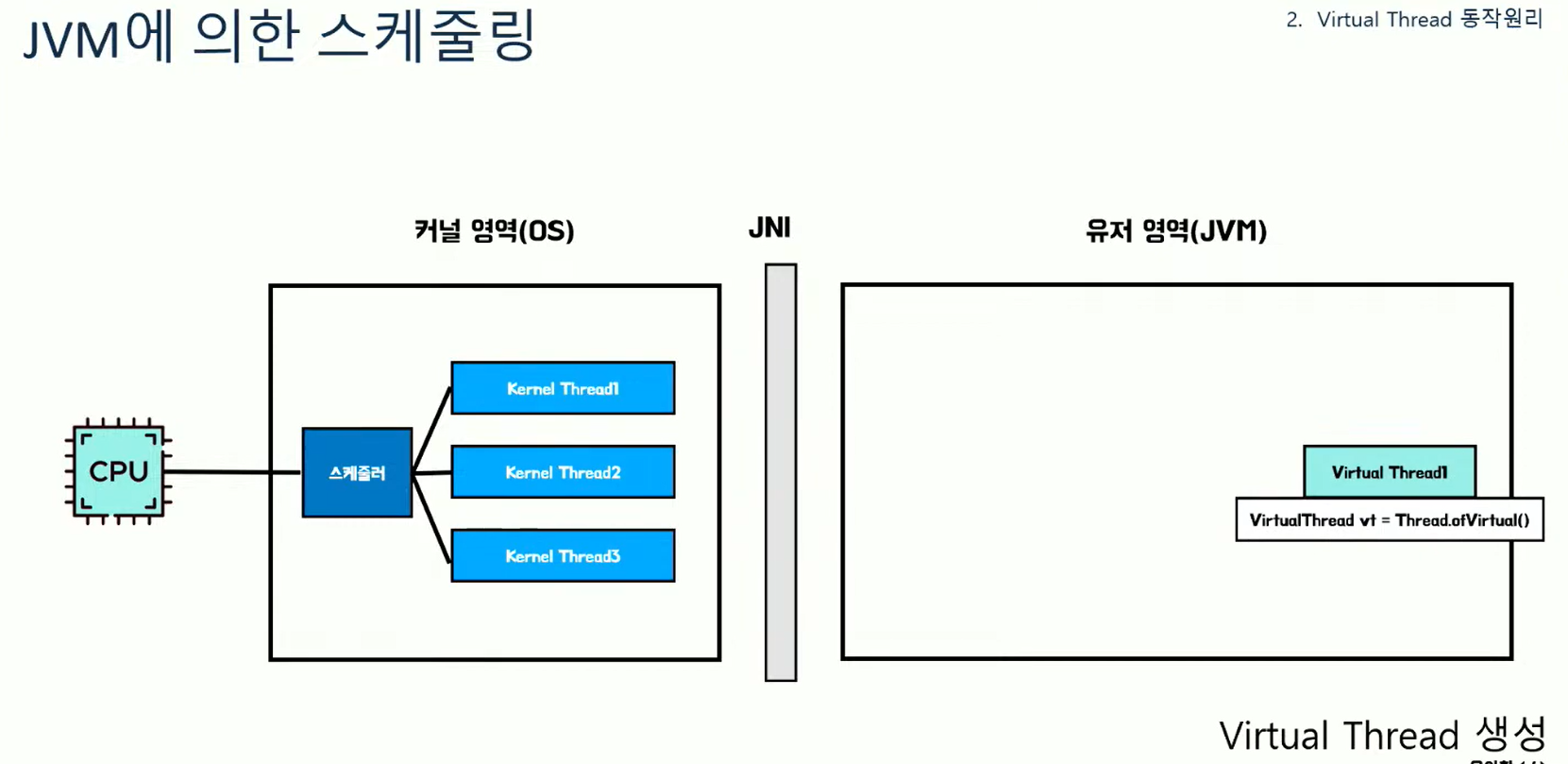
그렇다면 VT의 특징을 보자.
가상 스레드라고 불리고, JVM에 의해 스케줄링되며 캐리어 스레드와 1:N맵핑된다고 한다. 작업 단위가 Runnable이 아닌 Continuation이라는 새로운 작업 단위를 사용한다.

여기서 JVM에 스케줄링 된다는 부분을 보자. VT의 주석을 보면 OS가 아닌 JVM에 의해 스케줄링되는 스레드라고 VT를 설명하고 있다.

이걸 그림으로 보면 VT를 우리가 생성하면 유저영역에 생성되고, start를 하면 원래는 커널영역에 요청했는데 VT는 JVM내스케줄러에 의해 처리된다는 것을 추측할 수 있다.

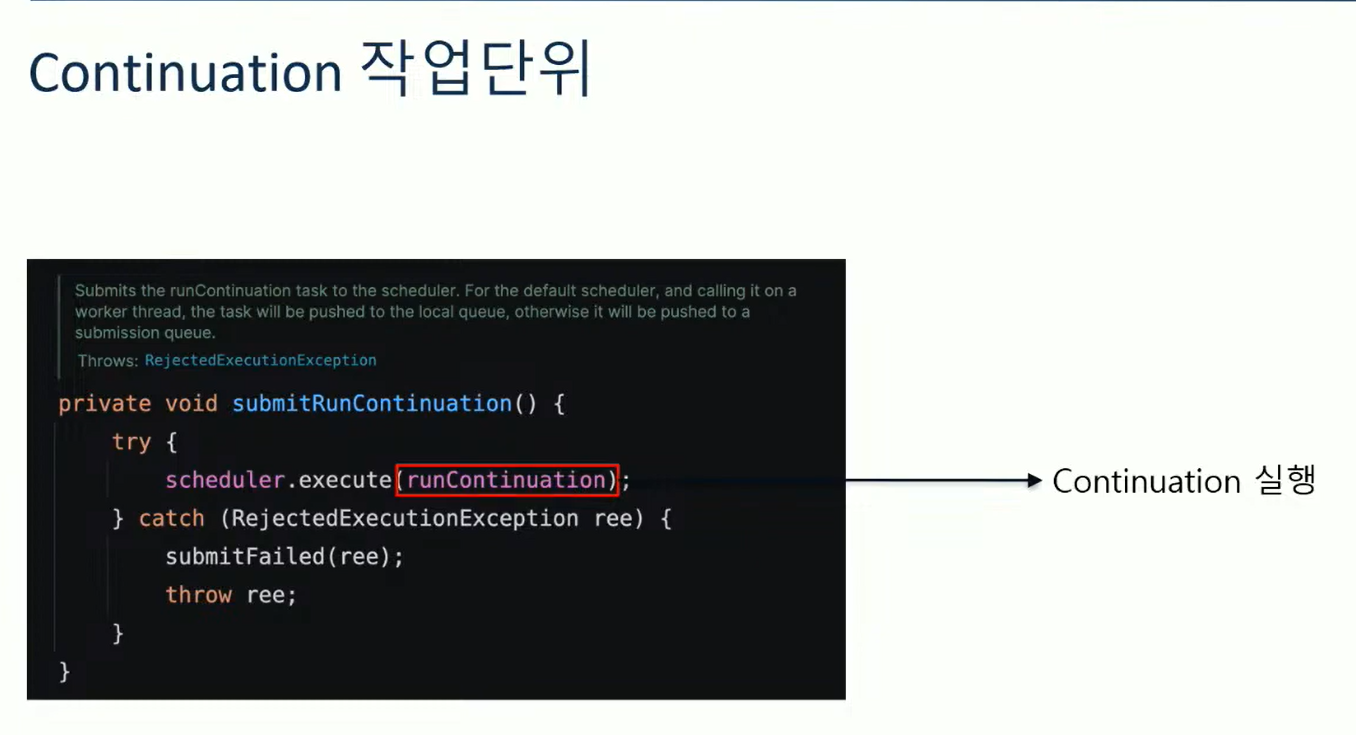
이걸 코드로 확인해보면 start를 했을 때 submitRunContinuation을 호출하게 된다.
submitRunContinuation이라는 메서드가 스레드를 실행하기 위해 task를 submit한다고 이해하면 된다. 여기서 작업 스케줄링을 한다고 이해하면 된다.

그래서 submitRuncontinuation을 보면 scheduler.execute를 하고 있다. 파라미터로 runContinuation이 있다. 우리가 처음 보는 녀석들이다. 이 중 scheduler는 우리가 예상한 JVM내의 스케줄러이다.

이 스케줄러가 VT의 스케줄링을 담당한다고 추측할 수 있다.
또한 VT의 클래스 정의를 보면 Executor 타입으로 scheduler가 존재하는 것을 볼 수 있다.



그럼 이 scheduler가 어떤 값으로 초기화되는 지 보기 위해 생성자를 본다.
생성자를 보면 DEFAULT_SCHEDULER로 초기화해주고 있다.

DEFAULT_SCHEDULER란 무엇일까? ForkJoinPool 타입이며 createDefaultScheduler 메서드에 의해 초기화되고 있다.

여기서 중요한 점이 static 변수이기 때문에 모든 VirtualThread는 동일한 스케줄러를 공유한다는 사실이다.
그리고 ForkJoinPool 매커니즘으로 스케줄링 한다는 것을 추측할 수 있다.

createDefaultScheduler 메서드를 살펴보자. 메서드를 보면 CarrierThread라는 ForkJoinWorker스레드를 사용한다.
그리고 병렬성을 현재 CPU의 코어 수로 설정하고 있다. 즉 worker스레드의 수가 CPU 코어 수가 된다.
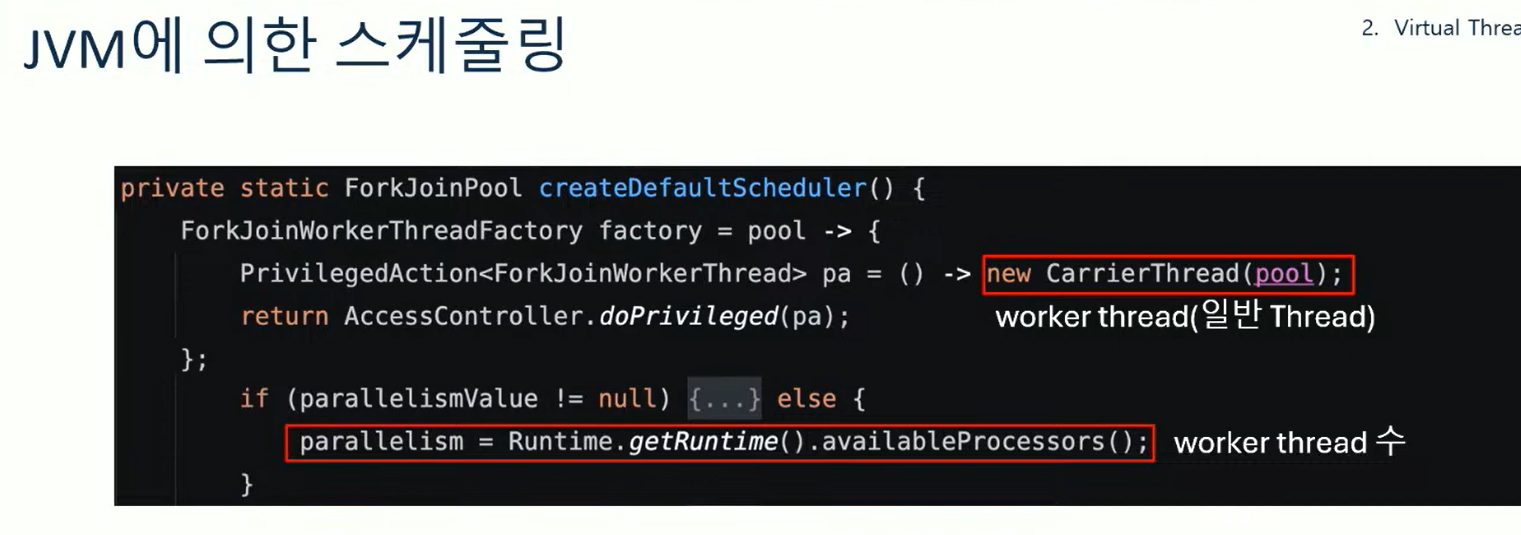
여기까지 봤을 때 우리가 앞서 봤던 스케줄러를 대략 알았다. 우선 ForkJoinPool을 사용하고, 코어수만큼의 캐리어 스레드를 만든다는 것을 볼 수 있다.

또한 ForkJoinPool은 내부적으로 Work Stealing 알고리즘이 있다. 그래서 WorkQueue에 각 task들이 있는데, 본인의 WorkQueue에 작업이 없으면 훔쳐오는 방식이다.

그렇다면 왜 이렇게 복잡하게 JVM내에서 스케줄링 하도록 변경되었을까?
이걸 생각해보면 일반스레드는 생성부터 관리까지 계속 OS와 통신해야하고 이로 인한 오버헤드가 있다.
하지만 VT는 그냥 JVM내에서 자바 객체 수준으로 처리할 수 있다. 이로인해 스레드의 생성과 시작이 빠를 수 있었다. (앞선 실험에서 본 것처럼)

다음으로 Continuation에 대해 살펴봐야 한다. 작업단위가 Runnable에서 Continuation이라는 새로운 단위로 한다.


그럼 Continuation이 무엇일까? 오래전부터 사용되던 개념이라고 한다.
유명한 코틀린의 코루틴을 살펴보자. 얘도 Continuation을 사용하도록 동작한다고 한다.
코루틴은 코루틴 컴파일러가 suspend 함수를 Coroutine으로 변경해서 실행한다고 한다.
그래서 그림을 보면 일반적으로는 Caller과 호출하면 함수가 다 실행하고 return문을 실행하면 제어권을 반환하고 끝난다.
하지만 코루틴 방식의 경우 (suspend) 중단이 가능해진다고 한다.
그래서 caller가 호출하면 어느정도 실행하다가 중단지점을 만나면 중단하고 다시 caller로 제어권을 반환한다고 한다. 이후 caller가 이어서 작업을 하다가 또 코루틴을 호출하면 중단지점부터 다시실행하는 방식이 가능하다고 한다.
이게 기본적인 Continuation의 동작방식이라고 한다.

그래서 Continuation을 정의하면 실행가능한 작업 흐름이며 중단이 가능해야하며 중단하다가 재게할 수 있어야 한다는 특징을 갖게된다.

이걸 코드로 살펴보면 일반적인 Runnable은 start running end를 모두 출력하고 끝난다.

하지만 continuation으로 바꾸면 start만 실행하고 중단했다가 다른 작업하다가 다시 running을 하다가 중단하고 이런식으로 가능하다고 한다.

그림으로도 표현해봤는데, 여러 Continuation을 관리하는 continuation scope가 존재하고 그 안에 Continuation들이 존재한다고 한다.
이 때 continuation1이 수행되고 있는 과정을 그림으로 표현한 상태이다.
그래서 continuation1은 작업을 실행하다가 yield라는 중단지점을 만나면 작업을 중단한다.



그리고 중단 지점을 스택에 기록하고, 그걸 힙으로 이동시킨다고 한다.

그리고 제어권은 다시 caller로 넘어가게 된다. 그 다음 caller가 continutation2를 실행시키면 힙에 저장해놨던 cont2의 정보가 다시 스택으로 올라가게 된다. 이후 cont2가 중단지점을 마주하게 되면 실행중이던 정보를 저장하고 힙에 다시 저장한다.


이 때 cont1을 다시 실행하면 cont1의 정보가 다시 스택으로 올라간다. 이런식으로 중단지점으로부터 다시 작업을 재게할 수 있다.

이걸 코드로 보면 cotinuationScope를 정의해놓고, continuation1을 생성했다. 이건 실행중로그를 찍고 중단했다가 다시 재게한다. 이 때 yield 라는 메서드가 보인다.
cont2로 동일하게 동작하도록 했다.
이걸 실행할때는 run을 번갈아가면서 한다.

그래서 실행결과를 보면 아래와 같다. 수행하다가 중지되고 수행하고 이런식으로 수행하게 되는 모습이다.

어쨋든 생각해보면 Continuation은 작업하다가 중단이 가능한 것이라고 이해하면 될 것 같다.
그렇다면 VT에서는 Continuation을 어떻게 활용할까? 필드에 Continuation 객체가 선언되어 있는 모습이다.
이게 작업 (task)을 의미하는 continuation이 된다.
그리고 그 밑에 runContinuation이 있다. 이건 Runnable타입인데 continuation을 실행해주는 람다라고 한다.


그래서 continuation을 초기화하는 부분을 보면 생성자에서 VThreadContinuation이라는 타입으로 현재 VT와 받은 task를 넘겨서 continuation을 만들고 있다. runContinuation은 VT의 private 메서드로 runContinuation이라는 메서드가 있어서 그걸 호출하고 있다.


runContinuation을 보면 continuation을 실행하는 역할을 한다.

그러면 앞에서 우리가 VT를 시작할 때 submitRunContinuation을 호출했었고, scheduler가 이걸 execute했었다. scheduler는 ForkJoinPool이었고, runContinuation은 continuation을 실행해주는 Runnable이었다. 즉, 스케줄러에다가 continuation을 실행해주는것이다.
그래서 여기까지 continuation이 어떻게 동작하는지 그림으로 살펴보자.
캐리어 스레드 마다 WorkQueue에 continuation들이 제출된다. (runContinuation이라는 Runnable들이 들어가게 되는 것)

그래서 우리가 VT는 start를 하게되면 스케줄러에 작업을 제출하는 것 (submitRunContinuation)이기 때문에 이 WorkQueue에 작업이 제출되는 것이다.
이제 Continuation을 실행하는 부분까지는 살펴봤다.

이 때 yield를 명시적으로 써야할까? 언제 VT가 yield될까? park메서드 라는게 있는데, 여기서 yielded필드에 yieldContinuation하고 있다. 즉, yield하고 싶으면 park 메서드를 호출해야 한다.

근데 park를 외부에서 호출하도록 도와주는게 있는데, 이게 LockSupport의 park메서드이다.
LockSupport의 park 메서드를 보면 현재 스레드가 VT일 때 virtual thread의 park를 호출하고 있다.
그래서 yield를 하기 위해서는 LockSupport의 park를 호출하면 된다는 것을 추론할 수 있다.

그리고 else문은VT가 아닐때 호출되는데 (일반스레드) 일반 스레드는 continuation을 지원안하는데 어떻게 되지? 라고 생각할 수 있다. 근데 이 U는 일반 스레드에서 보통 스레드를 block 할때 사용하는 메서드이다.
일반 스레드는 커널 스레드와 연결되기 때문에 block 시키려면 커널 스레드도 block시켜야해서 native메서드까지 호출하는 모습이다.


그래서 이 park은 thread.sleeep, block, CompletableFuture의 get 등 스레드를 block해야될때 호출되는 메서드라고 한다.

그래서 이 LockSupport의 park 메서드는 기존에는 커널스레드까지 블록되는 코드인 U.park만 존재했지만 VT부터는 VirtualThread의 park를 호출하도록 추가되었다. 즉, VT에서는 continuation의 yield를 호출 할 수 있도록 park가 호출된다고 이해하면된다.

이걸 그림으로 보면 WorkQueue에 2가지 작업이 있다고 가정하자. cont1이 먼저 수행되고 있는 상태이다. 이 때 cont2작업이 들어왔다.

근데 cont1이 yield되는 상황 즉, locksupport.park가 호출되는 상황이 왔다. (ex: Thread.sleep 등등)

그럼 cont1의 작업이 중단되고 하던 내용을 힙 메모리에 저장한 후 workqueue에서 제거한다고 한다.
그럼 cont2가 workqueue에 남게된다. 그래서 이어서 작업을 하게 된다.


그렇다면 이 복잡한 continuation을 왜 사용하게 되었을까? 우선 스레드는 작업 중단을 위해 커널스레드까지 중단해야 한다. 하지만 VT는 작업 중단을 위해 LockSupport.park를 호출하면 그게 continuation의 yield를 호출하는 구조이다.
이렇게 되었을 때 작업이 중단되어도 실제 스레드 (커널스레드와 연결된 플랫폼 스레드)는 블록되지 않고 다른 작업을 할 수 있게된다. 이렇게함으로써 논블로킹 IO처럼 동작할 수 있게 구현할 수 있는 것이다.
그리고 작업을 교체하는 과정에서 native 메서드를 호출할 필요도 없어서 이 오버헤드도 크게 줄게 된다.

그래서 요약하면 VT는 JVM 에 의한 스케줄링이 이루어지고, continuation이라는 작업 단위를 통해 스레드의 스케줄링 비용도 줄이고 논블로킹도 가능하게 만들었다.

다음으로 기존 스레드 모델을 가진 서버와 VT를 사용하는 서버 모델을 비교해보자.

아래는 기존에 우리가 사용하던 스레드 모델이다. (thread per request) 요청마다 스레드가 할당되었으며 이 톰캣 스레드 (플랫폼 스레드)는 OS의 커널 스레드와 1:1맵핑되는 모습이다.
이 상황은 플랫폼스레드가 2개밖에 없다고 가정한다.
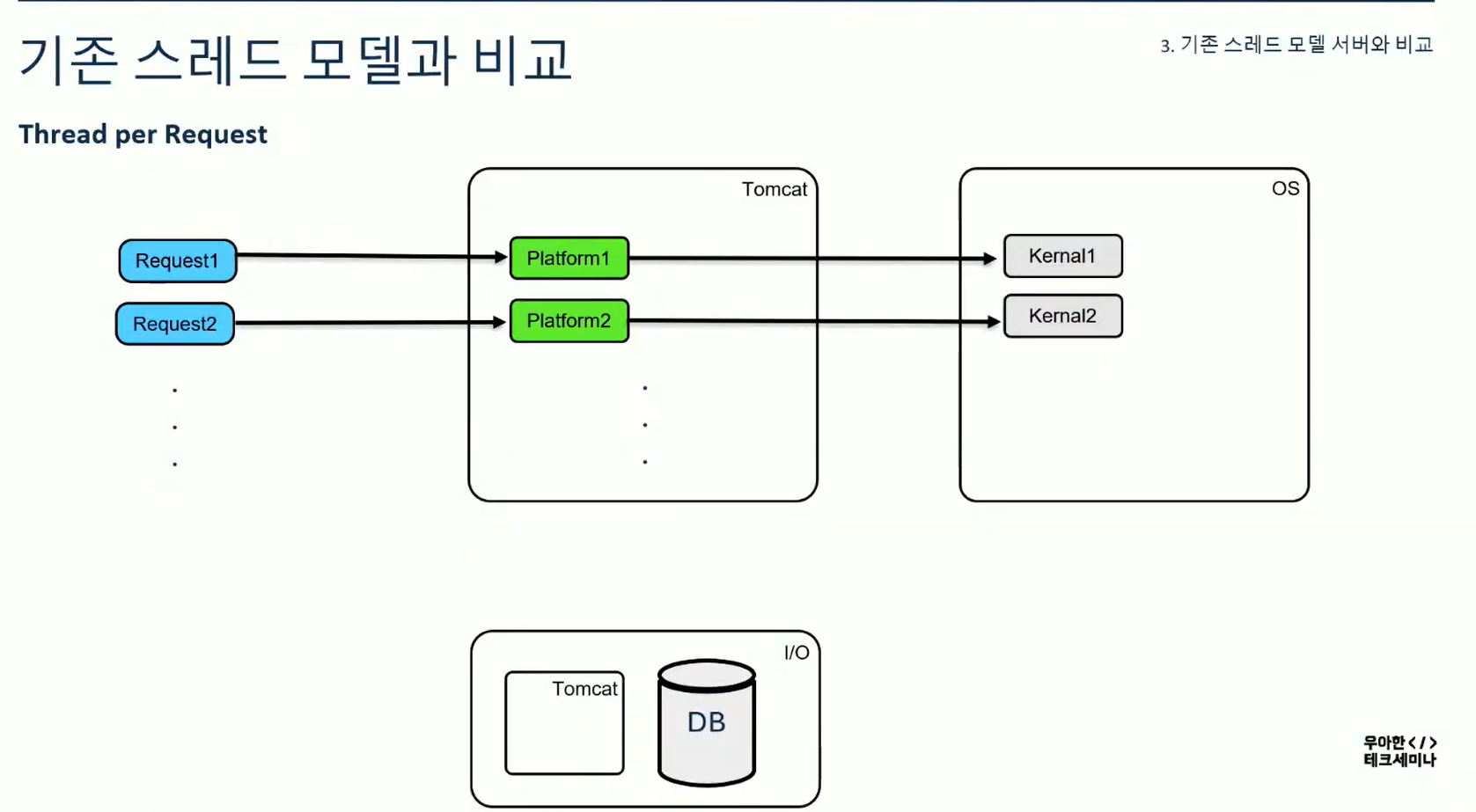
이 때 request2에서 DB요청을 하면 DB응답이 올 때까지 해당 스레드는 블로킹 된다.(LockSupport.park가 내부적으로 호출되었을 것이다) 그럼 커널스레드까지 블록된다.

이렇게 됐을 때 request3이 오면 더 이상 스레드가 없으니까 대기해야 한다.

대기하다가 DB로 부터 응답을 받으면 response가 나간 뒤 request3을 비로소 처리할 수 있게 된다.
이게 우리가 알던 thread per request방식이다.


이걸 VT를 사용하도록 설정을 아래처럼 바꾼다. newVirtualThreadPerTaskExecutor로 해주면 된다고 한다.

이렇게하면 아래처럼 바뀐다고 한다. request당 virtual thread와 맵핑이 되고, 캐리어 스레드가 OS의 커널스레드와 맵핑된다.

이 때 request2가 DB때문에 블로킹 된다. 마찬가지로 LockSupport.park가 호출된다. 그럼 내부적으로 continuation의 yield가 호출된다. yield를 하면 해당 작업은 suspend된다.

그럼 이 상황은 virtual thread가 캐리어 스레드로부터 분리되는 상황이 되는 것이다.

이 때 request3이 들어오면 새로운 virtual thread가 생성된다. 그럼 얘가 스케줄러에 의해 캐리어 스레드와 연결된다.

여기서 request2의 IO blocking이 끝났다.하지만 아직 캐리어 스레드가 없어서 대기한다.

이후 reuqest1이 response가 완료되면 캐리어스레드1에 request2가 붙어서 하던 작업을 계속 할 수 있다. 이런식으로 논블로킹이 동작한다.

즉, 정리하면 Continuation과 LockSupport의 park를 리팩토링 하여 논블로킹이 가능하도록 구현하였다고 요약할 수 있다.

다음으로 성능테스트이다.

VT가 일반 스레드 대비 얼마나 성능이 나올지, 어떤 상황에서 적용하면 좋을지 살펴본다.
일단 최소한의 환경을 구성했다고 한다.
서버는 Spring MVC이고 JVM Heap도 256MB정도로 했으며 ngrinder를 사용했다고 한다.
또한 I/O Bound 작업과 CPU Bound 작업을 나눠서 테스트했다고 한다.

결과를 보면 I/O Bound 작업의 경우 51% 높은 성능을보여주었고, CPU Bound작업은 더 낮은 성능을 보였다.

결과를 해석해보면 I/O Bound는 논블록킹으로 처리되서 높은 성능이 나오지만 CPU Bound는 결국 플랫폼 스레드위에 올라가서 수행되어야 한다. 그래서 오히려 VT가 플랫폼 스레드로 스위칭되고 이런 상황이 CPU Bound에서는 낮은 성능을 유발했다.
다만 일반 스레드 방식의 서버는 특정 vuser수 이상부터는 장애가 발생했다고 한다. 즉, 최대 처리량이 VT보다 낮다는 것을 의미한다.

다음은 WebFlux와 VT를 비교했다. 서버가 WebFlux로 변경되었다.
vuser는 500으로 테스트 했다.

결과를 보면 압도적인 것 같지만 요청량이 일정 기준을 넘어가면 Webflux의 처리량이 낮아졌다고 한다. 이건
메모리 부족 등으로 인한 리소스 이슈로 해석된다고한다.
(실제로는 성능 테스트 결과가 비슷하다고 한다)
다만 VT는 커널 스레드를 블락하지 않아서 컨텍스트 스위칭 비용이 높지 않아서 상대적으로 높은 성능이 나왔다고 해석한다.


요약을 하면 VT가 I/O Bound 작업 + 제한된 리소스에서는 높은 성능을 낼 수 있다.

이제 VT의 주의사항을 본다. 먼저 Pinned 현상이다. 즉, 캐리어 스레드가 블록킹 되는 상황이다.

캐리어 스레드 자체가 block 되어버리면 VT를 활용할 수 없는데, 이를 유발하는게 synchronized와 parallelStream을 사용할 때라고 한다. 이걸 감지 할 수 있는게 VM 옵션의 PinnedThreads 옵션을 줘서 감지 할 수 있다고 한다.

다만 synchronized 구문을 ReentrantLock으로 변경하면 synchronized로 인한 Pinned 현상은 사라진다고 한다.
pinned 현상은 실제로 많이 발생해서 이슈로 많이 올라와 있는 상황이다.


이러한 상황을 막기위해서는 사용중인 라이브러리를 모두 점검해야 한다.

다음 문제는 No Pooling이다. VT는 Pooling을 하면 안된다. 즉 VT는 필요할 때마다 스레드를 생성한다. 생성비용이 저렴해서 쓰고 GC가 일어나도록 하는것이 맞다고 한다.
즉, 오히려 스레드풀을 쓰면 병목이 될 수 있다.

ExecutorService에서도 unbounded로 VT를 만들도록 하고 있다.

다음으로 CPU Bound 작업이다. CPU Bound작업은 결국 캐리어 스레드 위에서 동작해야 하므로 논블로킹의 이점을 살릴 수 없다. 그러니 I/O Bound 작업 위주로 활용한다.

VT는 또한 스레드가 가볍기 때문에 스레드로컬 같은 곳에 무거운 객체를 넣는다거나하면 VT의 이점을 살릴 수 없게 된다.
JDK21에 ScopedValue라고 스레드로컬을 대체하는 개념이 나오는데, VT에서는 스레드로컬 대신 Scoped Value를 사용하면 좀 더 개선된다는 말이 있다고 한다. (필요하면 살펴보도록 한다)

마지막으로 배압 이슈이다.
기존에는 스레드가 부족하면 자연스레 요청을 처리하지 못하는데, VT는 무제한으로 생성하기 때문에 서버의 최대치로 스레드를 생성하려고 한다. 이 과정에서 하드웨어 리소스가 부족할 수 있고, VT를 적용하면 DB커넥션을 무한히 맺게 될 수 있어서 이 부분도 주의해야 한다.

결론을 내면 VT는 가볍고 빠른 논블로킹 스레드이다.
이를 실현하기 위해 JVM 스케줄링 + Continuation을 활용한다.
I/O Bound 작업 위주일때 사용하는 것이 좋다. 이는 러닝 커브가 적어서 쉽게 도입하기 좋다.

[Q&A]
Q. 코루틴에 비해 VT가 가진 장점이 궁금
A: 일단 2가지 개념을 혼동하면 안되는게 VT는 결국 스레드이다. 스레드의 대기시간을 줄이는 패러다임이다.
반면 코루틴은 루틴인데, 메서드의 대기시간을 어떻게 줄이냐에 따른 패러다임이라서 근본부터 다르다.
VT의 경우 thread per request의 처리량을 올리기 위한 것, 코루틴은 메서드 단위로 쪼개서 스케줄링하기 때문에 스레드보다 메서드가 더 작은단위라 더 높은 동시성 가능.

Q: 지금 사용중인 스레드풀 모델에서 VT로 바꾸는 과정은?
A: 톰캣을 사용할 때는 톰캣 설정을 바꾸고, 만약 스레드풀을 바꾼다하면 ExecutorService를 변경해서 진행하면 된다.

Q: 실제 운영환경 적용 경험은?
A: 운영에서는 안정성이 중요함. HW자원도 고려해야하기 때문에 성능테스트 후 적용예정. 아직은 적용 안함.

Q: Webflux는 이제 쓰지 않을지..?
A: Webflux도 reactive 프로그래밍이라 VT와는 패러다임이 다르다. VT는 배압조절도 안되며.. webflux는 함수형 프로그래밍이라 그쪽으로 처리하려면 webflux가 좋은 선택지 일 수 있다.

Q: 가상 스레드 할당 제한은 없는지 궁금
A: 없다. 가상 스레드가 너무 많으면 앞서 짚어줬듯이 주의해야 한다.

Q: DB Connection풀에서 발생하는 이슈 때문에 고민이다.
A: 해결을 위해 세마포어를 통해 배압을 조절하라고 한다.

Q: