[Why Streaming?]
데이터를 처리하는 역사를 따라가보면 Data Warehouse - Batching - Streaming 순으로 발전해왔다.
Data Warehouse
클라우드 이전 시절에는 Data Warehouse만을 사용하였고, 이 공간 자체는 한정적이지 엄격한 schema를 기반으로 분석을 위한 데이터만 추출하여 저장하는 방식으로 사용하였다.
그리고 데이터를 실제로 사용하는 시점은 데이터가 모두 이관된 이후 BI툴을 이용한 접근만이 가능하였다.
Batch
하둡의 Batch 시스템이 나오고나서 다양한 schema를 사용할 수 있었지만 여전히 배치가 끝난 후 데이터에 접근할 수 있었다.
Streaming
다양한 schema 뿐만 아니라 Ingestion (데이터를 빼오는 시점)에 바로 데이터에 접근할 수 있게되어 실시간으로 데이터를 활용할 수 있게 되었다.
스트리밍 데이터는 수천 개의 데이터 원본에서 연속적으로 생성되는 데이터를 말한다.
[Stateless, Stateful]
stateless
한 이벤트에 대해서 기존 상태랑 상관없이 처리하는 것.
단순연산. (ex: 메시지의 값에 3을 곱해라)
stateful
기존의 상태를 이해해야 하는것. (ex: 특정 이벤트가 몇번 일어났는가?)
스트림이 2개 있다고 가정하자.
- 광고의 노출
- 광고의 클릭
노출과 클릭은 서로 다른 이벤트인데, 이게 연결되어야지만 언제 노출되었고 언제 클릭되었다. 이런 지표를 모을 수 있다.

https://www.confluent.io/blog/crossing-streams-joins-apache-kafka/
Crossing the Streams – Joins in Apache Kafka | Confluent
An in-depth analysis of the various ways to join streams and tables in Apache Kafka's Streams API.
www.confluent.io
[Stream과 Table의 차이]
Stream: 레코드가 주루루룩 있는 것.
Table: 특정시간에 특정 상태를 나타내는 것.
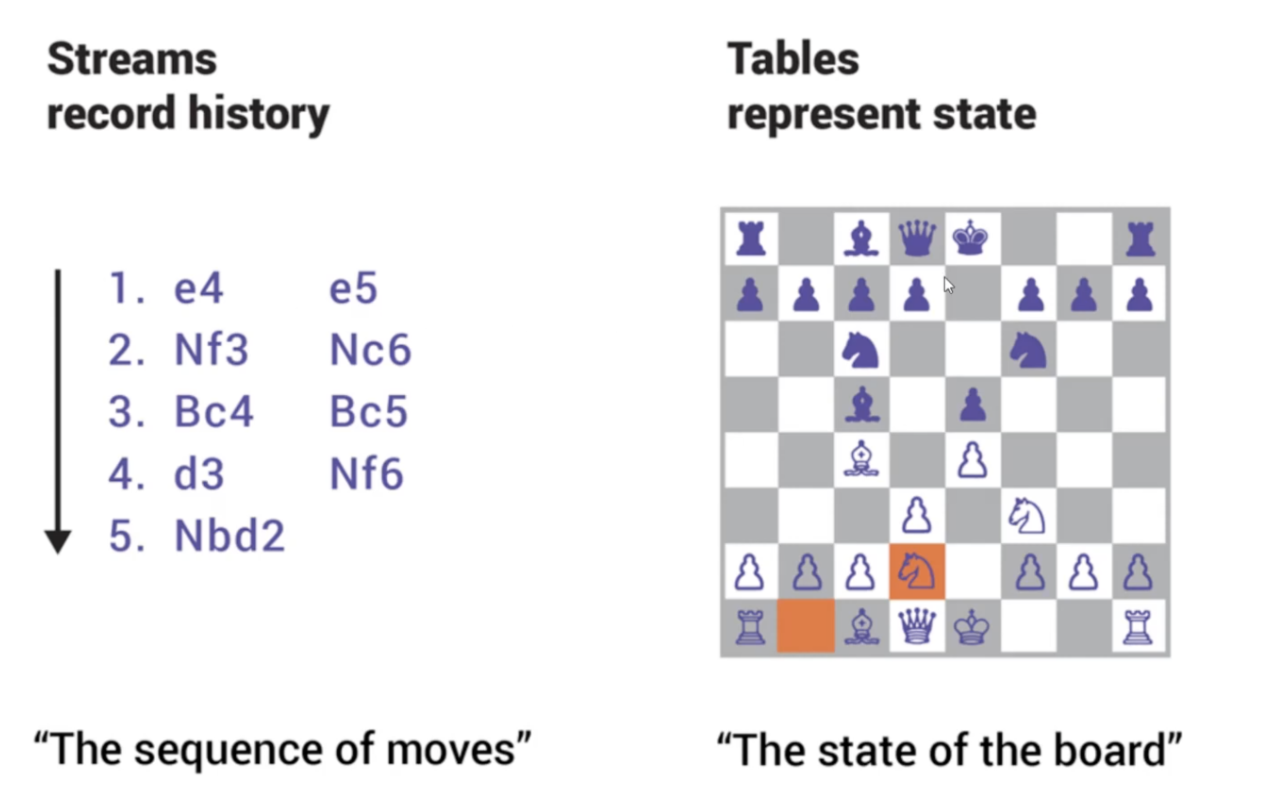
https://docs.confluent.io/5.3.0/ksql/docs/index.html
KSQL | Confluent Platform 5.3.0
Version 5.3.0 Docs KSQL and Kafka Streams » KSQL View page source KSQL What Is KSQL? KSQL is the streaming SQL engine for Apache Kafka®. It provides an easy-to-use yet powerful interactive SQL interface for stream processing on Kafka, without the need to
docs.confluent.io
[Stream Platforms]
Kafka
카프카 → 소설가 → 소설은 쓰는 것 → 쓰기에 최적화됨.
카프카는 Queue + Messaging을 합친 서비스.
스트림 프로세싱 도구들이 내장되어 있다.
이벤트가 매우 다양한 곳에서 쓰여지는데, 이벤트의 형태와 플랫폼 접근방법이 제각기이다.
이를 중앙에서 관리할 수 있는 구조가 필요했음.
Kafka는 이벤트를 중앙에서 통제할 수 있는 Pub/Sub구조를 통해 이를 실현함.
Pulsar
야후에서 만든 클라우드 환경에서의 분산 메시지 스트리밍 플랫폼.
kafka와 유사하게 Zookeeper, Broker를 사용한다.
Kafka는 Broker 자체에 메시지를 저장하지만 Pulsar는 Bookkeeper에 저장하는 구조를 가진다.
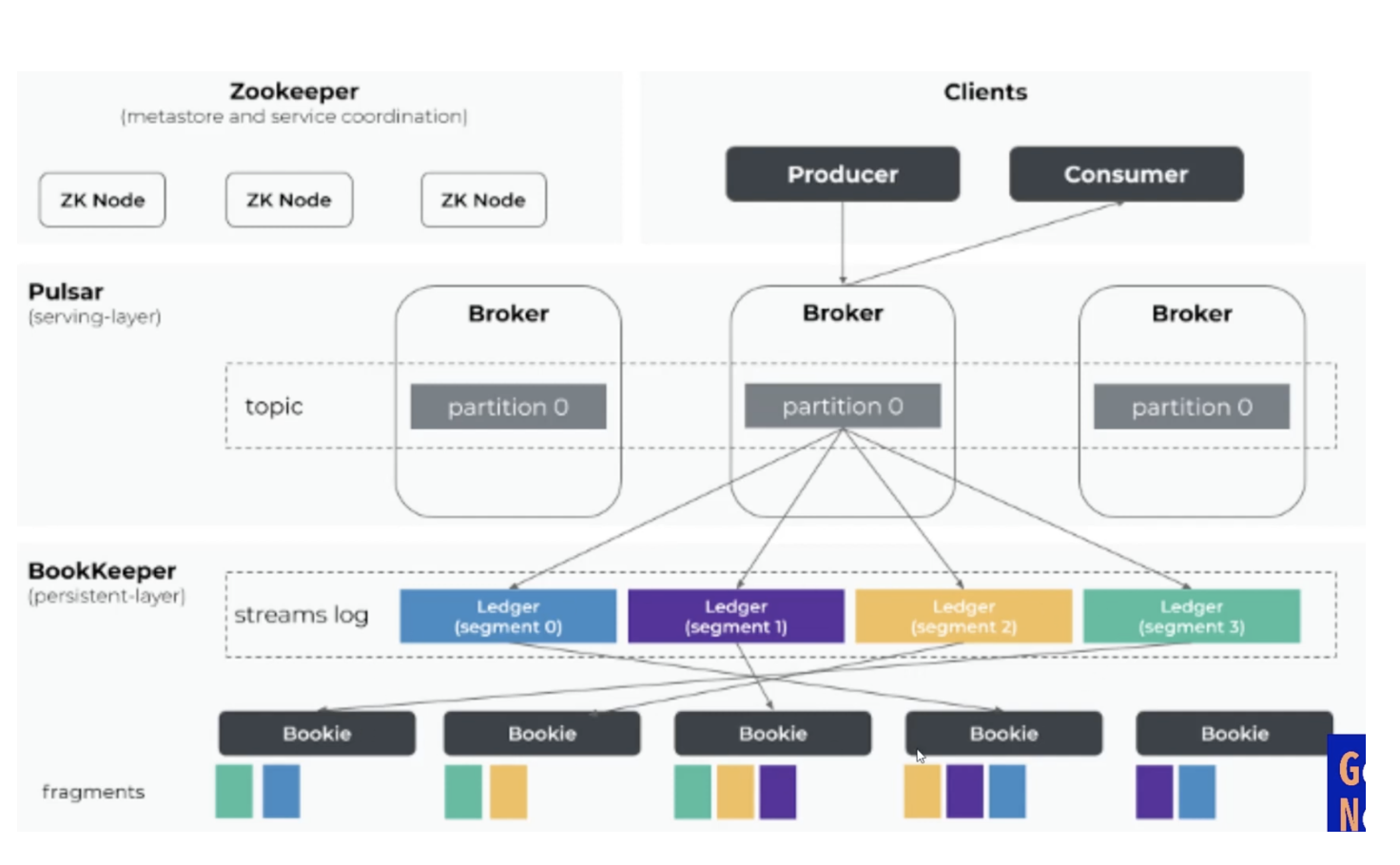
Difference of Pulsar, Kafka
Latency가 Kafka보다 더 낮다고 함.
kafka의 경우 토픽을 전용파일과 디렉토리에 저장하는데, Pulsar는 BookKeeper라는 곳에 저장하고 이를 저장한 후 인덱싱하는 구조로 사용한다.
Multi Datacenter기반의 아키텍쳐를 기본적으로 제공한다. (Kafka의 경우 Confluent 수준에서 제공함)
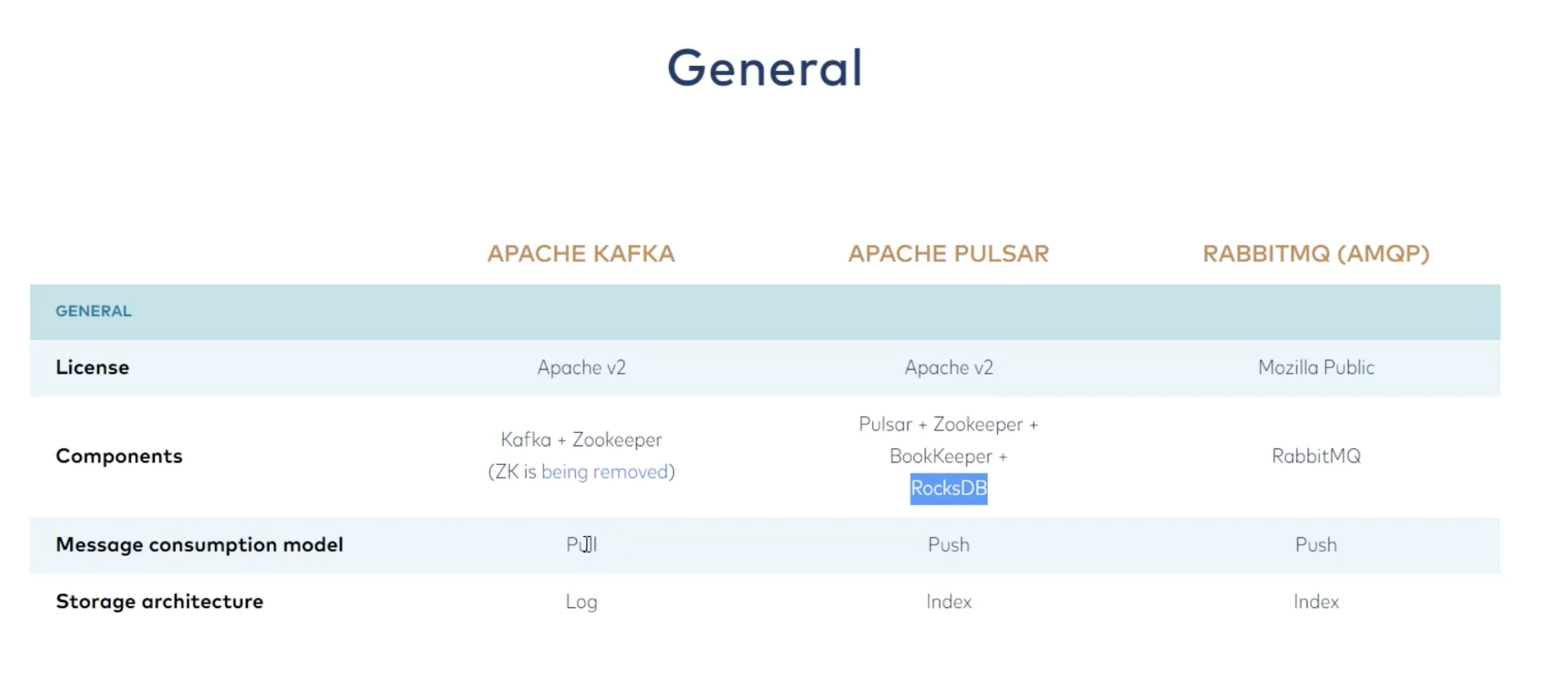
Kafka vs Pulsar vs RabbitMQ
Kinesis
아마존이 만든 스트리밍 플랫폼.
Kinesis의 경우 파티션을 줄이는 것도 가능하다고 함.
But 성능 지표면에서 Kafka가 압도적으로 앞선다는 결과가 다수 있어 Kafka를 훨씬 많이 씀.
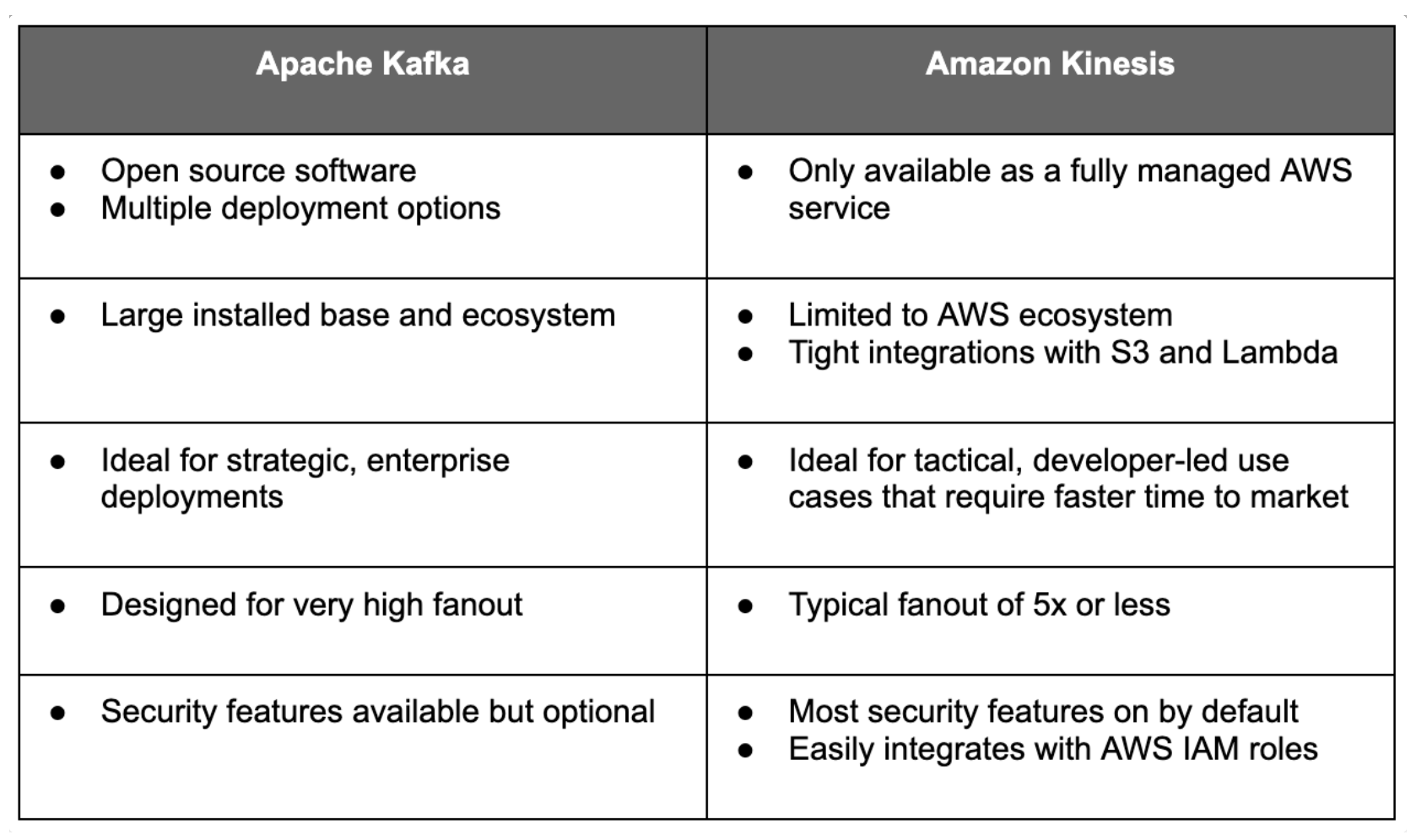
vs kafka

[참조]
Learning Apache Apex
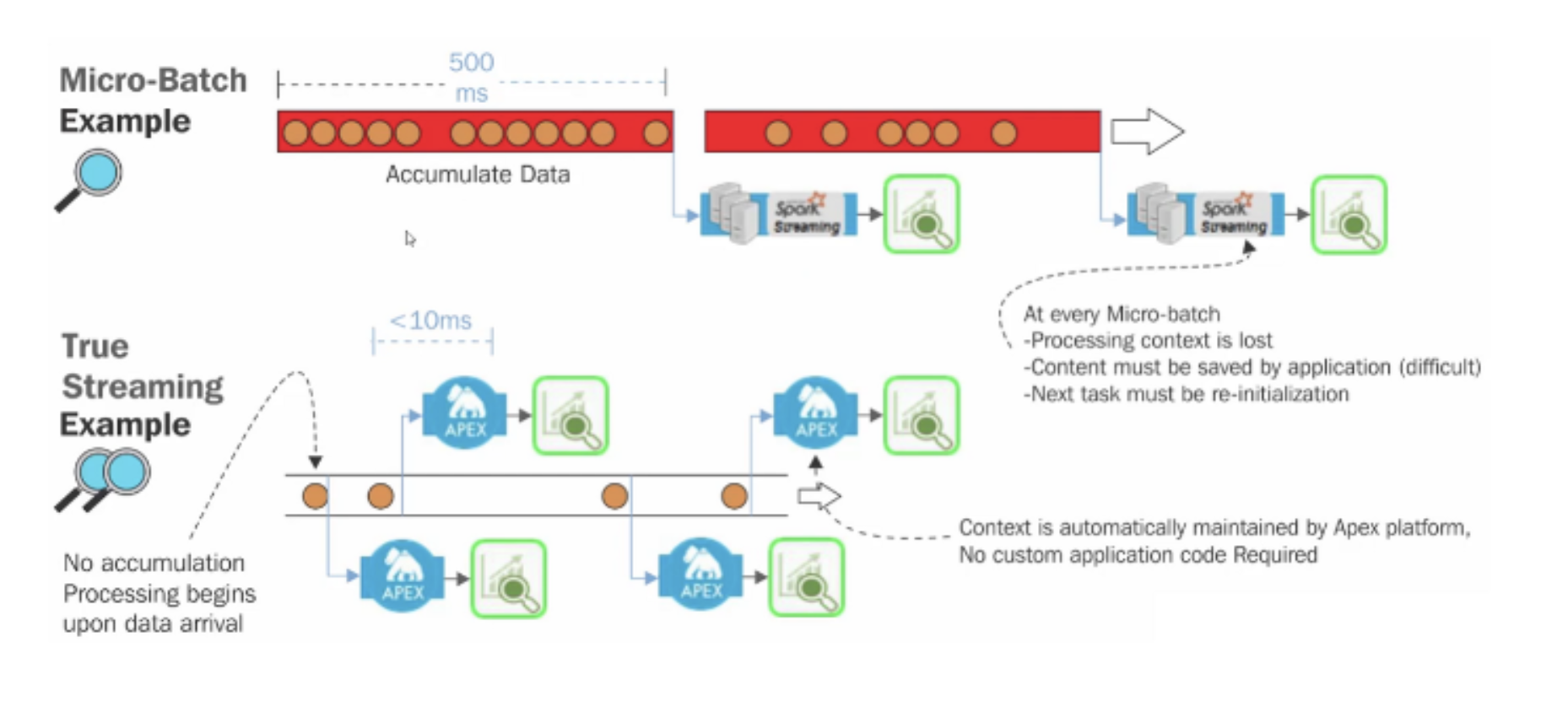
Native streaming versus micro-batch Let's examine how the stateful stream processing (as found in Apex and Flink) compares to the micro-batch based approach in Apache Spark Streaming. Let's look at … - Selection from Learning Apache Apex [Book]
www.oreilly.com
Introduction to Apache Pulsar — Concepts, Architecture & Java Clients
Apache Pulsar is an open-source distributed streaming platform which was originally created at Yahoo.
medium.com
https://rockset.com/blog/kafka-vs-kinesis-choosing-the-best-data-streaming-solution/
Kafka vs Kinesis: How to Choose
Which is the best stream processing solution for your needs and environment?
rockset.com
https://medium.com/flo-health/kinesis-vs-kafka-6709c968813
Kinesis vs. Kafka
What is better from latency/throughput perspective? Let’s find out through benchmarks!
medium.com