[1분 만에 시스템 상태 확인하기]
# 부팅 후 시간. Load Average 주로 확인
$ uptime
# System 메시지
$ dmesg | tail
$ vmstat 1
$ mpstat -P ALL
$ pidstat 1
$ iostat -xz
# 메모리 확인
$ free -m
$ sar -n DEV 1
$ sar -n TCP,ETCP 1
$ top
# 메모리 사용정보를 상세히 볼 수 있음.
$ cat /prox/meminfo
[파일 확인]
# system 로그 확인
/var/log/syslog
#timesync 설정 확인 - ntp
/etc/crontab
#CPU 정보 확인
/proc/cpuinfo[Command로 monitor]
vmstat : 메모리, 프로세스, 인터럽트, 페이징, 블록 I/O 정보 의 통계
- virtual memory statistics
- 가장 기본적인 시스템 모니터링 명령어이자, 시스템 리소스 이상 유무 판단하는 명령어
- 명령 옵션
- vmstat [options] [delay [count]]
- options
- -a, --active active/inactive memory
-f, --forks number of forks since boot
-m, --slabs slabinfo
-n, --one-header do not redisplay header
-s, --stats event counter statistics
-d, --disk disk statistics
-D, --disk-sum summarize disk statistics
-p, --partition <dev> partition specific statistics
-S, --unit <char> define display unit
-w, --wide wide output
-t, --timestamp show timestamp
- -a, --active active/inactive memory
- options
- 사용 예시
- vmstat : 현재 상태 보고
- vmstat [repeat_time] : repeat_time만큼 반복하여 상태 보고
- vmstat [repeat_time] [repeat_count] : repeat_time(초)마다 repeat_count회 반복한 통계 보고
- 첫라인은 boot된 이후의 상태 요약이므로 제외하고 보자
- vmstat [options] [delay [count]]
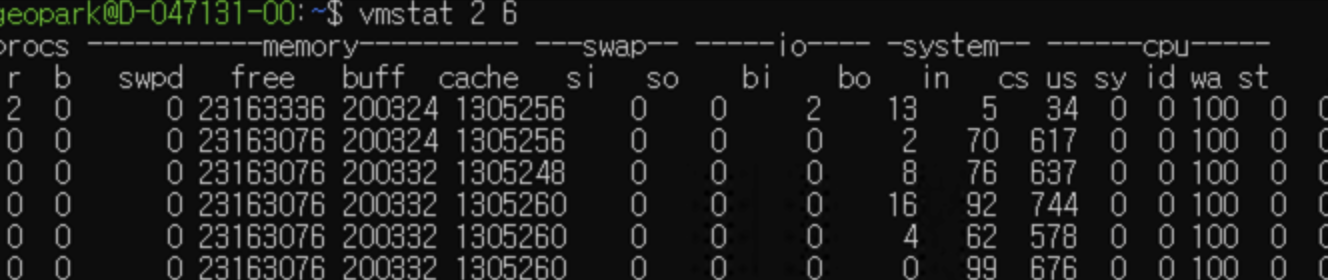
- 필드별 설명(주로 확인할 필드)
- procs(process)
- r(runnable) : CPU를 기다리는 run queue에 있는 프로세스(스레드)의 수
- b(blocked) : I/O 이벤트가 완료되기를 기다리며 blocked된 프로세스(스레드)의 수.
- disk I/O가 느리면 증가함
- system
- cs(context switch) : 초당 CPU context switch 횟수
- cpu (us + sy + id = 100%)
- us(user) : CPU가 사용자 수준(application) 코드를 실행한 시간 비율(%)
- wa : 입출력 대기
- procs(process)
- HW ↔ 필드

- r: running in queue ( CPU 수의 2 ~ 5배 이상일 경우 병목현상 의심, 멀티코어일 경우 조정)
- 실행 가능한 프로세스의 수
- Disk에서 memory 까지 로드가 되었으나 core가 busy 하여 대기중인 스레드 개수
- b: IO나 이벤트가 완료되기를 기다리며 sleep하는 스레드의 수 Disk의 IO가 느리면 뜬다고 함. ( 지속적으로 0이 아닌 숫자가 있는 경우 iostat 을 통해 자세히 확인해볼 것)
- core 에서의 작업을 모두 끝내고 disk 에 write 하려고 하나 자원할당받지 못하여 대기 하는 상태
- 성능 문제에서 가장 중요하게 봐야 할 필드
- cs: context switching이 얼마나 자주 일어나는가
- us: app이 system 커널값을 사용한다면 이 값이 올라갈거임
둘 중에 하나가 60이상이면 뭔가에 의해서 부하가 생기고 있다는 뜻임.
이상적인 CPU 사용은 us, id 작업 수행하는데 시간을 대부분 사용.
iostat : CPU 사용량, 디스크 및 파티션에 대한 IO 통계
- 명령 옵션
- iostat [repeat_time : repeat_time(초) 마다 반복하여 통계 보고
- iostat [options] [delay [count]]
- options :
- -c : cpu 사용량
- -d : 디스크 사용량
- -k : 킬로바이트로 정보 출력
- -m : 메가바이트로 정보 출력
- -p : 파티션 당 통계 포함
- -t : timestamp 출력
- -x : 확장 정보
- -z : 사용량이 0 인 정보 제외
- options :
- 필드별 설명(주로 확인할 필드). 리눅스 별로 다르지만, 필드 앞에 %가 붙어있다면 비율로 보면 된다.
- CPU 관련 필드
- iowait/await : I/O 작업으로 인해 CPU가 대기하는 시간
- Disk 관련 필드
- rrqm/s : 큐에 대기중인 초당 읽기 요청의 건수
- await : 요청된 I/O 평균 시간
- util : 요청한 I/O 작업을 수행하기 위해 사용한 CPU 시간 비율. 80%이상이면 확인해야봐야 함. (100%에 가까워지면 디바이스에 한계)
- CPU 관련 필드
iostat
iostat -s -h
iostat -x 2 2
iostat -dxctm 1
- await: io가 느려서 cpu가 대기하는 시간
- util: 80%이상이면 뭔가 이상할 수 있다는 징조임
- rqm/s: 조사하기
iostat 버전에 따라서 지표가 조금씩 다를 수 있음
iotop : 전체 프로세스의 I/O 통계
- 보안 문제때문에 root 또는 admin 권한이 있어야 실행 가능.
- root 계정으로 접속하거나 sudo iotop 으로 실행
- 명령 옵션
- iotop options
- -o : i/o가 발생중인 프로세스만 보여줌
-b : batch mode- -n num : 반복횟수 지정
- -p pid : 특정 프로세스에 대한 정보 출력
- -d sec : 업데이트 주기 설정 ( default : 1s)
- -u user : 특정 유저 모니터링
- -a :실행한 시점부터 누적되는 Read Write 량 측정
- -P : 스레드 제외, 프로세스만 출력
- (방향키로 정렬 가능)
strace : application들이 호출하는 system call과 signal을 추적해서 성능 저하 지점 또는 에러 지점 확인
- 옵션
- -s : strace를 통해 추적할 때 화면 혹은 파일에 뿌려줄 문자열 최대 길이(byte)
- -f : 여러개의 work 프로세스 또는 work 스레드를 만들어서 사용하는 application을 추적할 때 사용
- 이런 application에 사용하지 않으면 마스터 프로세스만 추적이 될 수 있다.
- -t : system call 간의 소요 시간 등을 측정하기 위해서 추적하는 동안 time stamp를 찍는다
- -p pid : 추적하려는 프로세스의 pid
https://brunch.co.kr/@alden/12
마법의 도구 strace
Linux Performance | 오늘 다룰 주제는 Linux에서 제공하는 최강의 디버깅 도구 중에 하나인 strace입니다. strace를 사용하는 방법과 활용하는 방법에 대해서 간단하게 다뤄보겠습니다. 사실 너무나도 많
brunch.co.kr
ltrace(libray trace) : 동적 라이브러리(user level)와 시그널 추적
system library쪽을 볼 수 있음.
- 프로그램에서 오류가 발생할 때 ltrace를 통해 종료된 시점에 호출된 function/method를 기반으로 trace하여 오류 지점을 찾는데 도움이 됨
top : 시스템의 상태를 전반적으로 파악(CPU, Memory, Process)
젤먼저 나오는 화면은 nomalize된 것임

- d (idle - 중요!!): 높을수록 시스템이 놀고 있다. 40밑으로 떨어진다는건 cpu로드가 60이상이다라는 뜻.
- io작업이 활발한 상태이거나, job 확인을 해봐야 할 것.
- wa : cpu가 io를 기다리고 있음 (2이하로 되는 것이 좋음)
- 이게 높으면 1을 눌러서 모든 cpu core에 대한 정보를 본다(아래 이미지처럼 모든 cpu 코어 현황이 나온다)
- wa가 계속 올라가면 뭔가 io쪽에 이슈가 있다고 보면 된다.
- 5이하가 적당하고, 높으면 살펴봐야함

- us: CPU 사용율
- 메모리쪽에 swap이 뜬다면 메모리가 부족해서 swap됐다는 뜻이므로 메모리 이슈가 있는지 체크할 필요가 있다.
free -m : 메모리 현황
- 메모리 현황
available 값을 보고 판단. 메모리가 부족하다면 buffer/cache 영역을 점점 확대해나간다.

- used: 사용중인 메모리 크기. free, buff/cache를 제외한 크기를 말함.
- shared: tmpfs (메모리 파일시스템) 등으로 사용되는 메모리. 즉, 여러 프로세스에서 공유해서 사용할 수 있는 메모리.
- buff/cache: 디스크에서 데이터를 가져오거나 저장할 때 매우 느리기 때문에, 이 과정을 빠르게 하기위해서 디스크에서 한 번 가져온 내용을 메모리의 캐시영역에 저장해놓음. 이 때 사용하는 영역을 버퍼와 캐시라고 부른다.
- buffer
- buffer cache로 블록디바이스 (HDD) 메타데이터를 저장.
- ex: 파일이름, 마지막 수정날짜
- cache
- page cache + slab가 합쳐진 것
- page cache: 저장 장치를 통해 한 번 읽어온 파일의 내용을 메모리에 저장하는 것. buffer는 메타데이터를 저장한다면 이건 실제 파일의 내용을 저장함.
- slab: 커널 내부에서 사용하는 메모리, 캐시
- page cache + slab가 합쳐진 것
- buffer
- buffer/cache 영역을 전부 반환했는데도 메모리가 부족하다면?
- swap영역을 확인 및 사용하게 된다. 하지만 swap을 사용하는 것은 성능저하를 야기하게 된다. swap영역조차 없을 경우 OOM Killer에 의해 프로세스들이 강제종료된다.
uptime
- load average를 확인.
-코어가 20개면 2000이 풀임
- 보통 이슈가 있을 때 확인 순서
uptime -> free -> vmstat -> iostat -> top
기타
- lscpu : CPU 정보를 볼 수 있음
- cpu모델명을 긁어서 구글링하면 자세한 스펙을 알 수 있기도 함.
- uname : 리눅스 커널 정보
- -a : 커널의 자세한 정보 보는 옵션
- disk write test
sudo dd if=/dev/zero bs=1G count=1 of=/data1/write_1GB_test oflags=dsync
[참조]
- https://www.youtube.com/watch?v=rwVLa9me7e4
- application의 latency가 증가한 상황을 가정으로 한 linux performance trouble shooting 데모 영상
- 위 영상 시나리오
- step 1 : top
- top으로 시스템 전반을 살피고, Cpu usage에서 us(user), sy(system), id(idle)을 보면 cpu bound 이슈가 아님을 체크
- step 2 : vmstat 1
- 1초간의 요약본
- procs 필드
- 영상에서는 procs의 r 옵션이 cpu를 점유 또는 기다리는 프로세스의 수 라고 함
- if (r > num CPU) : CPU staturated인 상태
- memory, swap 필드
- swpd : swap memory been used
- disk으로 swap된 메모리 공간이므로 느림 → 보통 마지막으로 이용됨
- if (swpd > 0 ) : 물리 메모리를 다 사용한 것
- swpd : swap memory been used
- step 1 : top
'Linux' 카테고리의 다른 글
| xfs, ext4 파일시스템의 차이 (0) | 2022.11.15 |
|---|---|
| Linux Monitoring (0) | 2022.11.13 |
| H/W 구성요소 (0) | 2022.11.02 |