[문제점]
Apache Kafka Client 2.4 버전이상에서 RoundRobin Partitioner를 사용할 경우 partition 메소드가 두 번 호출되면서 메시지가 파티션에 골고루 분배되지 못하는 현상이 있다.
[버그 재현: 메시지 4개를 생성하기]
//RR 파티셔너 사용
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class);
...
KafkaTemplate<String, Object> kafkaTemplate = new KafkaTemplate<>(new DefaultKafkaProducerFactory<>(props));
ObjectMapper obj = new ObjectMapper();
//forloop를 통해 메시지 4개를 생성
for(int i = 0; i < 4; i++) {
kafkaTemplate.send(TOPIC, obj.writeValueAsString("msg: "+i)).addCallback(new ListenableFutureCallback<>() {
@Override
public void onFailure(Throwable ex) {
logger.info(ex.toString());
}
@Override
public void onSuccess(SendResult<String, Object> result) {
logger.info("Partition num = " + result.getRecordMetadata().partition());
}
});
kafkaTemplate.flush();
sleep(500);
}
...결과로 파티션 0,2,4,6에 메시지가 들어갔다.
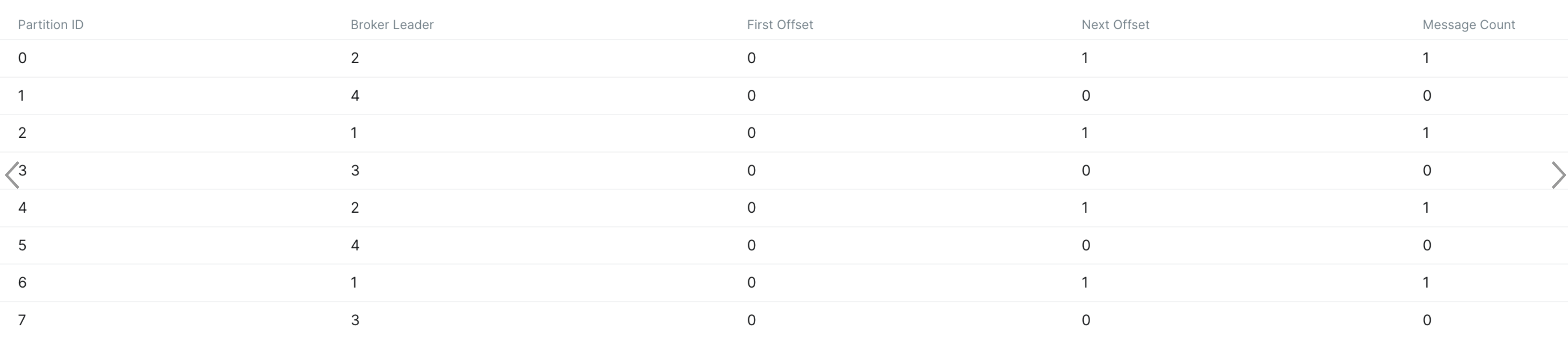
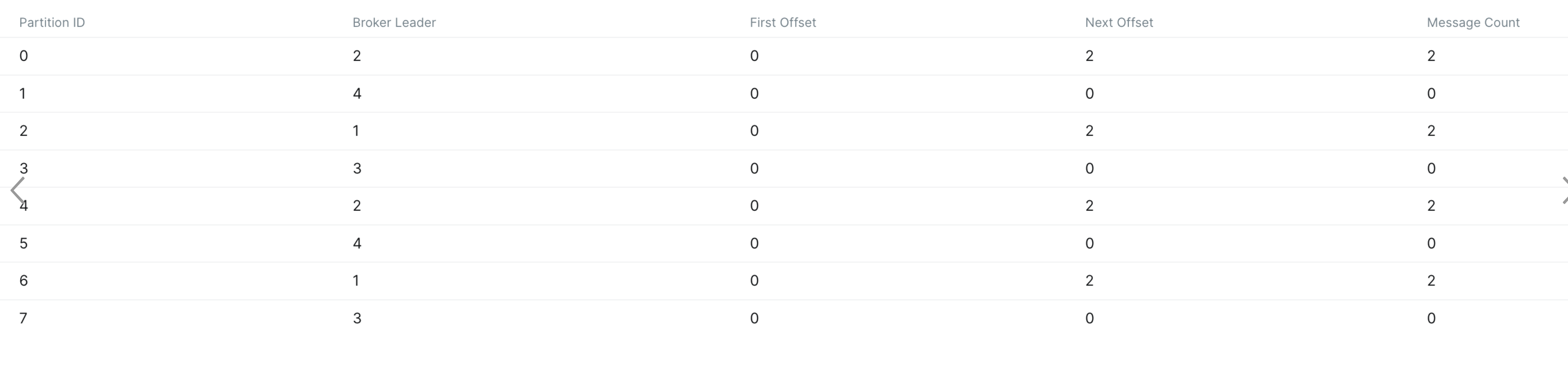
한 번 더 수행결과 마찬가지로 짝수 파티션에만 메시지가 유입되었다.
[Producer 동작방식 리마인드]

- Partitioner: 메시지가 어떤 파티션에 배치될 지 결정.
- RecordAccumulator: 할당된 파티션 번호를 바탕으로 배치에 메시지를 쌓는 역할.
- SenderThread: 배치에서 메시지를 읽어 실제로 브로커에 전송하는 역할
[원인 찾아보기]
이슈제기
이미 카프카 커뮤니티에 이슈제기가 되어있는듯하다.
https://issues.apache.org/jira/browse/KAFKA-9965
[KAFKA-9965] Uneven distribution with RoundRobinPartitioner in AK 2.4+ - ASF JIRA
issues.apache.org
RoundRobinPartitioner states that it will provide equal distribution of records across partitions. However with the enhancements made in KIP-480, it may not. In some cases, when a new batch is started, the partitioner may be called a second time for the same record:
RoundRobinPartitioner는 파티션 간에 레코드를 균등하게 분배할 것이라고 명시합니다. 그러나 KIP-480의 개선 사항으로 인해 그렇지 않을 수도 있습니다. 경우에 따라 새 일괄 처리가 시작되면 파티셔너가 동일한 레코드에 대해 두 번째로 호출될 수 있습니다.
KIP-480이후 RR 파티셔너를 사용할 경우 레코드가 불균형하게 호출되는 현상이 발생할 수 있다고 한다.
KIP-480
그렇다면 KIP-480의 개선사항은 무엇일까?
https://cwiki.apache.org/confluence/display/KAFKA/KIP-480%3A+Sticky+Partitioner
StickyPartitioner의 도입이었다.
StickyPartitioner는 RR의 단점 중 하나인 레코드를 매번 다른 파티션에 보내는 방식을 개선한 것으로, 배치가 가득차거나 linger.ms를 경과할 때 까지 메시지를 파티션에 "고정"하여 한 번의 배치에 가능한 많은 메시지를 실어보내는 방법이다.
StickyPartitioner의 경우 새로운 배치가 생성될 때 "고정" 파티션을 변경하는 방식으로 구현하였다고 한다.
이를 위해 Partitioner 인터페이스에서 onNewBatch 라는 메서드가 신규추가되었다.
아래 문서의 소스코드 파헤치기 부분을 보면 onNewBatch의 용도와 호출시점을 이해할 수 있다. 다음으로 진행하려면 꼭 읽어보고 진행하는 것을 추천..!
https://jaemni.tistory.com/entry/Sticky-Partitioner
Sticky Partitioner
[개요] Apache Kafka 2.4 버전 이후부터 사용가능한 파티셔너이다. 기존에는 RR방식으로 동작했는데, 이 방식에 대한 단점이 있어 이를 보완한 방법 [파티셔닝?] Kafka의 메시지는 key/value 의 형태로 구
jaemni.tistory.com
[문제점 확인하기]
그렇다면 Sticky가 도입되면서 RR에는 어떤 영향을 주었길래 문제가 발생한 것일까..?
Apache Kafka 2.4 이전 KafkaProducer 구현
2.4버전 이전까지 RoundRobinPartitoner의 이름은 DefaultPartitioner였다.
public class DefaultPartitioner implements Partitioner {
private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();
public void configure(Map<String, ?> configs) {}
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
if (keyBytes == null) {
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (availablePartitions.size() > 0) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
} else {
// hash the keyBytes to choose a partition
return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.get(topic);
if (null == counter) {
counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());
AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);
if (currentCounter != null) {
counter = currentCounter;
}
}
return counter.getAndIncrement();
}
public void close() {}
}private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
...생략
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compressionType, serializedKey, serializedValue, headers);
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
if (transactionManager != null && transactionManager.isTransactional())
transactionManager.maybeAddPartitionToTransaction(tp);
//append하고 끝난다.
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs);
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
}
Apache Kafka 2.4 이후 KafkaProducer 구현
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
...생략
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
...생략
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
if (result.abortForNewBatch) {
int prevPartition = partition;
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
// producer callback will make sure to call both 'callback' and interceptor callback
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
}문제발생 시나리오
- partition번호를 받아온다.
- accumulator.append를 통해 메시지를 추가하려는 시도를 했을 것이고, RR의 특성상 항상 새로운 배치에 메시지를 넣으려고 한다. 그러므로 result에는 항상 abortForNewBatch값이 true로 넘어온다.
- if(result.abortForNewBatch) 안에 또 다시 partition 메서드가 있으므로 다음 번 파티션번호를 받아온다.
- 결과적으로 partition이 2번 호출되어서 문제점이 재현되었다.
즉, StickyPartitioner가 도입되면서 KafkaProducer 코드가 변경되었고, 이 부분에 대해 RoundRobinPartitioner에서는 대응하는 코드가 누락되면서 문제가 발생한 것. (항상 abortForNewBatch가 true여서 partition 메서드가 두 번 호출된다)
[해결방법]
방법1: KafkaProducer.java를 수정한다 (현실성 없음)
파티셔너의 경우 인터페이스를 제공해서 구현하는 형태로하면되지만 KafkaProducer의 경우 수정을 하더라도.. 기존 라이브러리와 혼합하여 적용하기가 어렵다.
// KafkaProducer#doSend
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
...
// first time we call partitioner
int partition = partition(record, serializedKey, serializedValue, cluster);
...
log.trace("Attempting to append record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// try to append the record, and abort when new batch
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// new batch case
if (result.abortForNewBatch) {
int prevPartition = partition;
// partitioner.onNewBatch(record.topic(), cluster, prevPartition);
// here, we bypass the partition() call if `onNewBatch` throw exception
try {
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
// 2nd time we call partitioner. If onNewBatch doesn't get implemented, we won't call it
partition = partition(record, serializedKey, serializedValue, cluster);
} catch (UnsupportedOperationException e) {
// ignore the exception since the partitioner doesn't care about new batch case
}
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
...방법2: RoundRobin의 버그를 수정한 커스텀 파티셔너를 구현한다.
https://github.com/apache/kafka/pull/11326/files
KAFKA-9965/KAFKA-13303: RoundRobinPartitioner broken by KIP-480 by jonmcewen · Pull Request #11326 · apache/kafka
RoundRobinPartitioner behaviour was broken by sticky partitioning (KIP-480). This patch addresses the behavioural issue caused by the second call to partition() after onNewBatch(), in a predicatabl...
github.com
public class BugFixRoundRobinPartitioner implements Partitioner {
/**
* The "Round-Robin" partitioner - MODIFIED TO WORK PROPERLY WITH STICKY PARTITIONING (KIP-480)
* <p>
* This partitioning strategy can be used when user wants to distribute the writes to all
* partitions equally. This is the behaviour regardless of record key hash.
*/
// private static final Logger LOGGER = LoggerFactory.getLogger(RoundRobinPartitioner.class);
private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();
private final ConcurrentMap<String, Queue<Integer>> topicPartitionQueueMap = new ConcurrentHashMap<>();
public void configure(Map<String, ?> configs) {
}
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
@Override
public int partition(
String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
Queue<Integer> partitionQueue = partitionQueueComputeIfAbsent(topic);
Integer queuedPartition = partitionQueue.poll();
if (queuedPartition != null) {
// LOGGER.trace("Partition chosen from queue: {}", queuedPartition);
return queuedPartition;
} else {
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (!availablePartitions.isEmpty()) {
int part = Utils.toPositive(nextValue) % availablePartitions.size();
int partition = availablePartitions.get(part).partition();
// LOGGER.trace("Partition chosen: {}", partition);
return partition;
} else {
// no partitions are available, give a non-available partition
return Utils.toPositive(nextValue) % numPartitions;
}
}
}
private int nextValue(String topic) {
AtomicInteger counter =
topicCounterMap.computeIfAbsent(
topic,
k -> {
return new AtomicInteger(0);
});
return counter.getAndIncrement();
}
private Queue<Integer> partitionQueueComputeIfAbsent(String topic) {
return topicPartitionQueueMap.computeIfAbsent(topic, k -> {
return new ConcurrentLinkedQueue<>();
});
}
public void close() {
}
/**
* Notifies the partitioner a new batch is about to be created. When using the sticky partitioner,
* this method can change the chosen sticky partition for the new batch.
*
* @param topic The topic name
* @param cluster The current cluster metadata
* @param prevPartition The partition previously selected for the record that triggered a new
* batch
*/
@Override
public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
Queue<Integer> partitionQueue = partitionQueueComputeIfAbsent(topic);
partitionQueue.add(prevPartition);
}
}'Kafka > Producer' 카테고리의 다른 글
| Kafka Producer 성능 테스트, 튜닝 (0) | 2023.04.22 |
|---|---|
| Log Compaction (0) | 2023.03.05 |
| BuiltIn Partitioner (0) | 2023.03.05 |
| Kafka Producer Basic Architecture (0) | 2023.03.03 |
| Sticky Partitioner (0) | 2022.12.03 |